Closed
Bug 363529
(jsbcopt)
Opened 18 years ago
Closed 13 years ago
Optimize JS bytecodes
Categories
(Core :: JavaScript Engine, defect, P2)
Core
JavaScript Engine
Tracking
()
RESOLVED
WONTFIX
People
(Reporter: brendan, Assigned: dmandelin)
References
Details
(Keywords: meta)
Attachments
(12 files, 22 obsolete files)
|
(deleted),
image/png
|
Details | |
|
(deleted),
text/plain
|
Details | |
|
(deleted),
image/png
|
Details | |
|
(deleted),
text/plain
|
Details | |
|
(deleted),
image/png
|
Details | |
|
(deleted),
text/plain
|
Details | |
|
(deleted),
patch
|
brendan
:
review+
|
Details | Diff | Splinter Review |
|
(deleted),
patch
|
brendan
:
review+
|
Details | Diff | Splinter Review |
|
(deleted),
patch
|
shaver
:
review+
|
Details | Diff | Splinter Review |
|
(deleted),
image/png
|
Details | |
|
(deleted),
text/plain
|
Details | |
|
(deleted),
text/plain
|
Details |
JS bytecode interpretation has not been optimized based on profiles and direct instrumentation since 1997 or so. This bug will track progress improving bytecode efficiencies, matching bytecodes to common cliches, consolidating common sequences and reducing interpreter overhead.
/be
| Reporter | ||
Comment 1•18 years ago
|
||
This filters edges accounting for < 1% of the grand total bytecode count, to avoid making an over-connected graph.
/be
| Reporter | ||
Comment 2•18 years ago
|
||
| Reporter | ||
Comment 3•18 years ago
|
||
| Reporter | ||
Comment 4•18 years ago
|
||
Big-picture analysis and comments welcome here. Also help fixing dependent bugs.
/be
Status: NEW → ASSIGNED
Priority: -- → P1
Summary: optimize JS bytecodes → Optimize JS bytecodes
| Reporter | ||
Comment 5•18 years ago
|
||
| Reporter | ||
Comment 6•18 years ago
|
||
Cutoff is .5% now for more detail, yet still visualizeable.
/be
Attachment #248353 -
Attachment is obsolete: true
| Reporter | ||
Comment 7•18 years ago
|
||
More detailed graph from gmail mini-session: http://wiki.mozilla.org/Image:Filtered_gmail_bytecode_graph.png
/be
{kind=link}
Comment 8•18 years ago
|
||
How about putting the actual percentages themselves in the graph?
| Reporter | ||
Comment 9•18 years ago
|
||
I haven't figured out how to get the weights to show up, even as thinner or thicker edges. Anyone with more GraphViz skilz, please help.
/be
Comment 10•18 years ago
|
||
s/weight=/label=/ does the trick.
| Reporter | ||
Comment 11•18 years ago
|
||
Attachment #248363 -
Attachment is obsolete: true
| Reporter | ||
Updated•18 years ago
|
Attachment #248403 -
Attachment description: dot file for filtered graph of gmail mini-sessionn → dot file for filtered graph of gmail mini-session
| Reporter | ||
Comment 12•18 years ago
|
||
s/weight/label/g
Attachment #248403 -
Attachment is obsolete: true
| Reporter | ||
Comment 13•18 years ago
|
||
Note that the labels are fractions of outgoing bytecode dispatch counts, not incoming. So you'll see them sum > 1 if you sum across the node into which several come.
Perhaps it would be better to label the absolute counts, so we could see what's hot and what's not.
/be
Comment 14•18 years ago
|
||
Oh yes, agreed. I had misunderstood that. (should probably filter by incoming too?)
| Reporter | ||
Comment 15•18 years ago
|
||
With labels telling counts of successors to bytecodes dispatched.
/be
Attachment #248415 -
Attachment is obsolete: true
| Reporter | ||
Comment 16•18 years ago
|
||
Brian, how'd you get around bugzilla's 300K limit? I uploaded to the wiki again:
http://wiki.mozilla.org/Image:Filtered_gmail_bytecode_graph.png
/be
| Reporter | ||
Comment 17•18 years ago
|
||
(In reply to comment #14)
> Oh yes, agreed. I had misunderstood that. (should probably filter by incoming
> too?)
No, because the outgoing counts from op1 to all op2 that succeed it will sum in all cases to the total count for op2 provided op1 is not a branch -- i.e., if op1 and op2 are in a basic block, or op1 always flows into the leader op2 of the successor basic block.
The important edges are the high count ones flowing from a non-branch. So it may be worth filtering branches, but I thought I'd leave things maximally visible (and the code simple) for now.
/be
| Reporter | ||
Comment 18•18 years ago
|
||
(In reply to comment #17)
> (In reply to comment #14)
> > Oh yes, agreed. I had misunderstood that. (should probably filter by incoming
> > too?)
>
> No, because the outgoing counts from op1 to all op2 that succeed it will sum in
> all cases to the total count for op2 provided op1 is not a branch -- i.e., if
> op1 and op2 are in a basic block, or op1 always flows into the leader op2 of
> the successor basic block.
I ignored the filtering effect -- we leave out edges with count < .5% of the grand total of all bytecodes dispatched.
Also, above in "the outgoing counts from op1 to all op2", I should have written more clearly. What I mean, for any op2, the sum of all labels for all op1 to that op2 should be the total count of op2 executions, ignoring filtering.
/be
Comment 19•18 years ago
|
||
Dotted, dashed, solid, bold by segmenting the edges into quarters, after sorting (experiment in readability). Perl hack that does it next.
Not having trouble with 300kb limit because for whatever reason my PNGs are coming out -way- smaller than yours. This one is 27kb-ish?
Comment 20•18 years ago
|
||
In case anyone else is interested.
Comment 21•18 years ago
|
||
Comment 22•18 years ago
|
||
Attachment #248427 -
Attachment is obsolete: true
Attachment #249120 -
Attachment is obsolete: true
| Reporter | ||
Comment 23•18 years ago
|
||
My brain hurts. I don't see how your patch can work (edges not used, nonzeroedges not used where it seems it might need to be). What's more, I can't see how to avoid sorting along each row to get busy columns to the front, then sorting along rows, and finally making a sorted row map.
If this is not minimal, please show me the light.
/be
Attachment #249131 -
Attachment is obsolete: true
Attachment #249133 -
Flags: review?(crowder)
| Reporter | ||
Comment 24•18 years ago
|
||
Tidy a bit.
/be
Attachment #249133 -
Attachment is obsolete: true
Attachment #249135 -
Flags: review?(crowder)
Attachment #249133 -
Flags: review?(crowder)
| Reporter | ||
Comment 25•18 years ago
|
||
The GraphVis-generated PNG for my gmail mini-session is too big, as usual, so I've updated http://wiki.mozilla.org/images/e/e5/Filtered_gmail_bytecode_graph.png.
Anyone know how to get OS X GraphViz to make smaller PNGs?
/be
{kind=link}
Attachment #248361 -
Attachment is obsolete: true
| Reporter | ||
Comment 26•18 years ago
|
||
Attachment #248357 -
Attachment is obsolete: true
Attachment #248358 -
Attachment is obsolete: true
Attachment #248408 -
Attachment is obsolete: true
Attachment #248414 -
Attachment is obsolete: true
| Reporter | ||
Comment 27•18 years ago
|
||
| Reporter | ||
Updated•18 years ago
|
Attachment #248421 -
Attachment is obsolete: true
| Reporter | ||
Updated•18 years ago
|
Attachment #249137 -
Attachment description: filtered graph for perfect.js → perfect.png
Comment 28•18 years ago
|
||
Comment on attachment 249135 [details] [diff] [review]
C only approach, seems to require sort x sort | sort, v2
Yeah, that's better. Might be cool to tidy this up a bit (maybe guard with preprocessor flag (DEBUG?)?) and make it generatable/clearable from some shell native func?
Attachment #249135 -
Flags: review?(crowder) → review+
Comment 29•18 years ago
|
||
(In reply to comment #23)
> Created an attachment (id=249133) [edit]
> C only approach, seems to require sort x sort | sort
>
> My brain hurts. I don't see how your patch can work (edges not used,
> nonzeroedges not used where it seems it might need to be). What's more, I
> can't see how to avoid sorting along each row to get busy columns to the front,
> then sorting along rows, and finally making a sorted row map.
>
> If this is not minimal, please show me the light.
>
> /be
>
Yeah, I stopped using the edges and went with count/total to segment by quarters (not mathematically the same), instead of using the actual sort position. Your newer patch is better.
| Reporter | ||
Comment 30•18 years ago
|
||
Simpler patch avoids keeping the extra book that I thought might be handy (total stored per predecessor opcode, length of sorted non-zero-count successors for each predecessor), and loses stability, so data looks slightly different.
That's because related edges have the same count, but the quartiling has to cut them into separate buckets differently depending on sort instability. Too bad; a bug? Comments welcome.
I added #ifdef JS_OPMETER bracketing and otherwise cleaned up.
/be
Attachment #249153 -
Flags: review?(crowder)
| Reporter | ||
Comment 31•18 years ago
|
||
To shorten my last comment into a question: perhaps all edges with the same count should go in the same quartile?
/be
Comment 32•18 years ago
|
||
Comment on attachment 249153 [details] [diff] [review]
avoid sort x sort, losing stability w.r.t. previous data
(most of the following are style questions for my own edification, not critiques of the patch)
Would be nice if there were a #defined value for the max opcodes for building the static array "succeeds". Any chance you'll get bit by JSOP_GETPROP2 and JSOP_GETELEM2? I didn't look very closely. Is using the magic number 256 in your loops more appropriate than js_NumCodeSpecs?
> + if (count != 0 && SIGNIFICANT(count, total)) {
isn't (count != 0 && SIGNIFICANT(...)) redundant? Should nedges or total ever be 0 after the first loop? Worth asserting about (or closing fp and bailing)?
Looks good.
Attachment #249153 -
Flags: review?(crowder) → review+
Comment 33•18 years ago
|
||
(In reply to comment #31)
> To shorten my last comment into a question: perhaps all edges with the same
> count should go in the same quartile?
>
> /be
>
That's one of the things I considered when I just went for count/total in my original C-version. It ends up being a comparison by value instead of by position in a not-stably sorted array. Not real quartiles, then, though.
| Reporter | ||
Comment 34•18 years ago
|
||
(In reply to comment #32)
> (From update of attachment 249153 [details] [diff] [review] [edit])
> (most of the following are style questions for my own edification, not
> critiques of the patch)
>
> Would be nice if there were a #defined value for the max opcodes for building
> the static array "succeeds".
There is: JSOP_LIMIT -- thanks for reminding me. But see next patch for why it's not used as the "columns" dimension.
> Any chance you'll get bit by JSOP_GETPROP2 and JSOP_GETELEM2?
No, the decompiler just uses these internally, they're never stored.
> Is using the magic number 256 in
> your loops more appropriate than js_NumCodeSpecs?
No (no point in testing zeroed cells), but JSOP_LIMIT is faster and better than js_NumCodeSpecs.
> > + if (count != 0 && SIGNIFICANT(count, total)) {
>
> isn't (count != 0 && SIGNIFICANT(...)) redundant? Should nedges or total ever
> be 0 after the first loop? Worth asserting about (or closing fp and bailing)?
No, nedges is an overestimate, because we haven't computed total before the first loop and we don't want to use it during the loop, before it is in fact the grand total.
/be
| Reporter | ||
Comment 35•18 years ago
|
||
Quartiles are distorted to include higher-cost edges having the same cost as any that fall in the upper quartile, in order to avoid splitting edges with the same label into two different styles.
Checking in shortly.
/be
Attachment #249135 -
Attachment is obsolete: true
Attachment #249153 -
Attachment is obsolete: true
Attachment #249176 -
Flags: review+
| Reporter | ||
Comment 36•18 years ago
|
||
| Reporter | ||
Comment 37•18 years ago
|
||
| Reporter | ||
Comment 38•18 years ago
|
||
Attachment #249139 -
Attachment is obsolete: true
| Reporter | ||
Comment 39•18 years ago
|
||
Attachment #249137 -
Attachment is obsolete: true
| Reporter | ||
Comment 40•18 years ago
|
||
Latest image is uploaded at http://wiki.mozilla.org/Image:Filtered_gmail_bytecode_graph.png
Direct link to "high resolution" version is http://wiki.mozilla.org/images/e/e5/Filtered_gmail_bytecode_graph.png
/be
Attachment #249140 -
Attachment is obsolete: true
| Reporter | ||
Comment 41•18 years ago
|
||
Y.dot and Y.png come from a run of Y.js, the applicative order Y combinator demo. Y.js is of course included with SpiderMonkey, but short:
// The Y combinator, applied to the factorial function
function factorial(proc) {
return function (n) {
return (n <= 1) ? 1 : n * proc(n-1);
}
}
function Y(outer) {
function inner(proc) {
function apply(arg) {
return proc(proc)(arg);
}
return outer(apply);
}
return inner(inner);
}
print("5! is " + Y(factorial)(5));
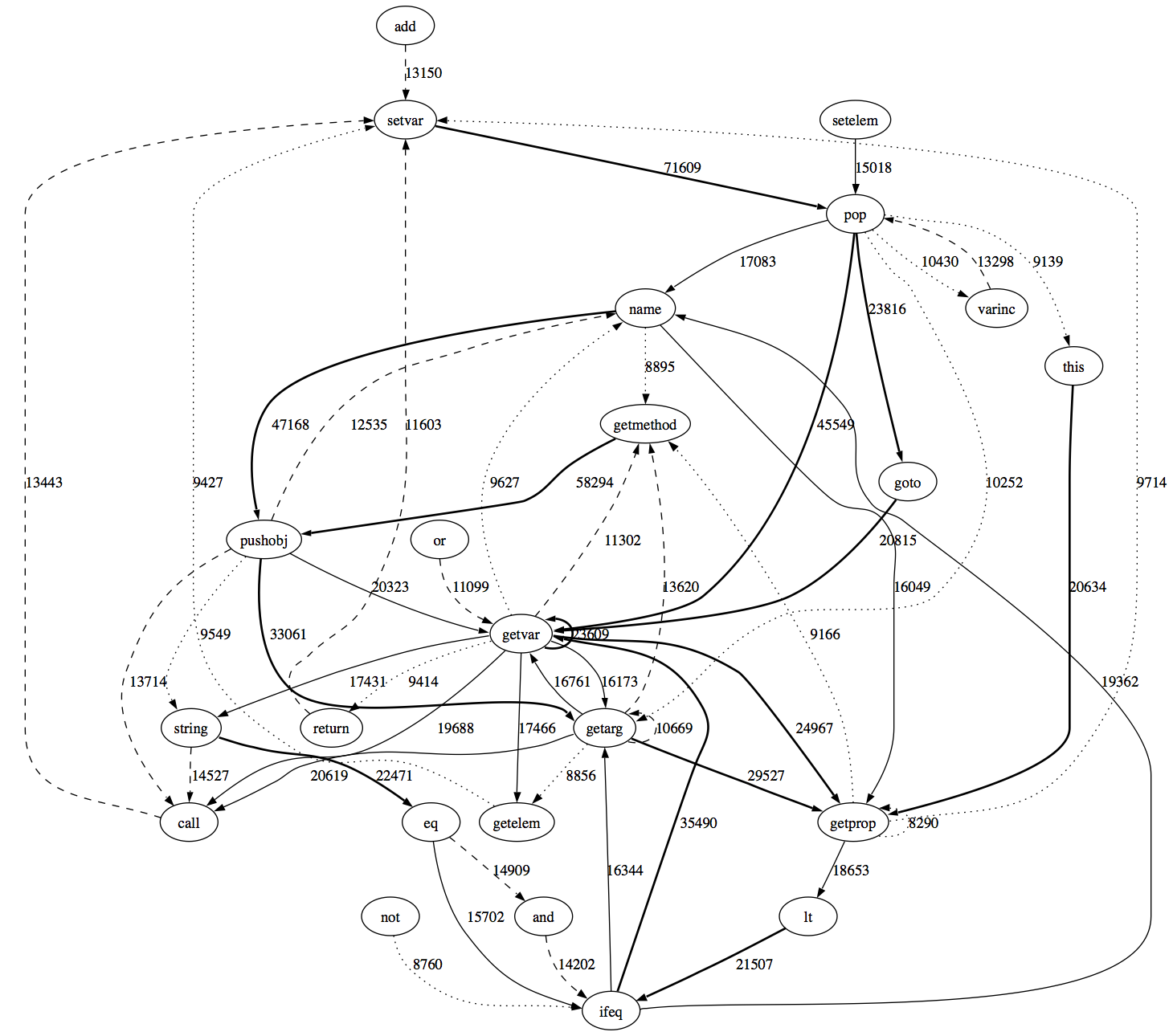
The low call counts help to understand the algorithm a bit, if you know JS bytecode already. More JSOP_NAME -> JSOP_PUSHOBJ evidence for bug 363530, and some JSOP_RETURN -> JSOP_PUSHOBJ higher-order functional goodness.
/be
| Reporter | ||
Comment 42•18 years ago
|
||
We should reorganize jsopcode.tbl with a global review after the dependency bugs are fixed. We can try to reclaim bytecode, e.g. JSOP_PUSHOBJ and JSOP_GETMETHOD which are to be replaced by a patch for bug 363530, as we go, adding as few as possible but leaving related bytecodes widely separated. The global cleanup after should try to put related bytecodes together, and look for other opportunities to speed up decoding.
It would be interesting, given the PUSHOBJ -> CALL edges I'm seeing, to histogram the number of actual arguments passed when running Firefox from startup through a gmail mini-session, e.g.
/be
| Reporter | ||
Comment 43•18 years ago
|
||
Oh, forgot to remind myself (and anyone else who needs it) to change JSXDR_BYTECODE_VERSION when making backward-incompatible changes to jsopcode.tbl. Adding a new bytecode at the end should not require this, but it would be nice to change it for such cases too.
I hope I have my backward and forward directions correct:
backward-compatible: new code runs on old profile with saved XUL.mfasl
forward-compatible: old code runs on new profile with saved XUL.mfasl
We don't worry about forward compatibility across major releases, or at least we haven't, since profile data formats may change incompatibly. This is not a good policy, and perhaps now is the time to change it (or Mozilla 2, if 1.9 is already too far gone).
/be
Comment 44•18 years ago
|
||
Because fastload is a generated cache, we really don't need to worry about forward or backwards incompatibility: we blow away the fastload cache whenever the buildID changes. It's not like a data-storage format.
| Reporter | ||
Comment 45•18 years ago
|
||
(In reply to comment #44)
> Because fastload is a generated cache, we really don't need to worry about
> forward or backwards incompatibility: we blow away the fastload cache whenever
> the buildID changes. It's not like a data-storage format.
Cool, I wondered about that.
Lots of JS embeddings use XDR, though, so we need to keep JSXDR_BYTECODE_VERSION moving forward when we "ship". Not sure what "ship" means -- not nightly Firefox builds of course.
/be
| Reporter | ||
Comment 46•18 years ago
|
||
Important #ifdef JS_OPMETER change from always-true #ifdef METER_OP_PAIR guard around op = JSOP_STOP in js_Interpret.
/be
Attachment #249176 -
Attachment is obsolete: true
Attachment #249219 -
Flags: review+
| Reporter | ||
Comment 47•18 years ago
|
||
Good thing I tested without JS_OPMETER defined :-/.
/be
Attachment #249219 -
Attachment is obsolete: true
Attachment #249221 -
Flags: review+
| Reporter | ||
Comment 48•18 years ago
|
||
Checking in jsapi.c;
/cvsroot/mozilla/js/src/jsapi.c,v <-- jsapi.c
new revision: 3.296; previous revision: 3.295
done
Checking in jsinterp.c;
/cvsroot/mozilla/js/src/jsinterp.c,v <-- jsinterp.c
new revision: 3.310; previous revision: 3.309
done
/be
Comment 49•18 years ago
|
||
It would be interesting to know what percentage of getvar, setvar and getarg access the first two or four local vars / arguments. Specialized opcodes like getarg1 or setvar0 would save two byte reads to fetch the index, if they're used often enough it could be worth the effort.
For comparison, CIL (a.k.a. MSIL) has special opcodes to load the first four arguments and to load or store the first four local variables.
| Reporter | ||
Comment 50•18 years ago
|
||
(In reply to comment #49)
> It would be interesting to know what percentage of getvar, setvar and getarg
> access the first two or four local vars / arguments. Specialized opcodes like
> getarg1 or setvar0 would save two byte reads to fetch the index, if they're
> used often enough it could be worth the effort.
> For comparison, CIL (a.k.a. MSIL) has special opcodes to load the first four
> arguments and to load or store the first four local variables.
Lots of VMs do this, it's a good idea. Here are some stats gathered using the next patch, from another startup/load-gmail/click-on-a-message:
bytecode slot 0 slot 1 slot 2 slot 3 slot 4 slot 5 slot 6 slot 7
======== ======= ======= ======= ======= ======= ======= ======= =======
getarg 49015 17388 4797 3574 917 425 23 20
setarg 1164 112 4 42 0 0 0 0
getvar 43795 22463 14960 11942 6049 4646 1007 1621
setvar 11808 8506 5120 4106 2588 1434 557 481
incvar 30 211 396 10 857 161 0 4
decvar 0 0 6 0 2 0 0 0
varinc 4364 2675 640 693 31 641 56 115
argdec 0 0 0 1 0 0 0 0
vardec 158 0 0 0 0 0 0 0
getgvar 14 0 4 6 2 0 7 0
setgvar 2 0 1 1 1 1 1 1
Interesting that we have some busy functions with many args/vars, but the low four of each dominate most rows. I'll file a dependent bug on this idea in a minute.
/be
| Reporter | ||
Comment 51•18 years ago
|
||
Attachment #249411 -
Flags: review?(crowder)
| Reporter | ||
Updated•18 years ago
|
Alias: jsbcopt
Comment 52•18 years ago
|
||
Comment on attachment 249411 [details] [diff] [review]
meter slot ops for slots 0-7
+ for (j = 0; ; j++) {
+ if (j == HIST_NSLOTS)
+ break;
Why not just
+ for (j = 0; j < HIST_NSLOTS; j++) {
+ for (j = 0; j < HIST_NSLOTS; j++)
+ fprintf(fp, " %7lu", (unsigned long)slot_ops[i][j]);
Is it your intention to reuse j here, even though it is the loop counter for the enclosing loop? This section looks odd in general to me...
Attachment #249411 -
Flags: review?(crowder) → review+
| Reporter | ||
Comment 53•18 years ago
|
||
(In reply to comment #52)
> (From update of attachment 249411 [details] [diff] [review] [edit])
> + for (j = 0; ; j++) {
> + if (j == HIST_NSLOTS)
> + break;
>
> Why not just
> + for (j = 0; j < HIST_NSLOTS; j++) {
It seemed clearer to make the loop test parallel to the other case that breaks, the one that reuses j:
> + for (j = 0; j < HIST_NSLOTS; j++)
> + fprintf(fp, " %7lu", (unsigned long)slot_ops[i][j]);
> Is it your intention to reuse j here, even though it is the loop counter for
> the enclosing loop? This section looks odd in general to me...
This reuse of j is within a then clause ending in a break. It saves writing the first (outer j loop) as a hunt for non-zero counts, breaking early when it finds such a count; then testing whether j reached HIST_NSLOTS and continuing the outer i loop if so (all counters for this i-op were zero), and only then writing the final (innermost, in the patch) j-loop.
I'll make the outer j-loop canonical, since the parallel if-then-break scheme obviously didn't help 'splain any of this ;-).
/be
| Reporter | ||
Comment 54•18 years ago
|
||
Landed:
Checking in jsapi.c;
/cvsroot/mozilla/js/src/jsapi.c,v <-- jsapi.c
new revision: 3.299; previous revision: 3.298
done
Checking in jsinterp.c;
/cvsroot/mozilla/js/src/jsinterp.c,v <-- jsinterp.c
new revision: 3.314; previous revision: 3.313
done
/be
Attachment #249411 -
Attachment is obsolete: true
Attachment #249455 -
Flags: review+
| Reporter | ||
Updated•18 years ago
|
Depends on: js-propcache
| Reporter | ||
Comment 55•17 years ago
|
||
This is just to get back to where we were. More JS_OPMETER ifdef'ed work to come, but I'd like to land this ASAP.
/be
Attachment #305953 -
Flags: review?(shaver)
| Reporter | ||
Comment 56•17 years ago
|
||
The .5% cutoff sure leaves a lot of ops out, and focuses the mind on some very common ops that ought to be close together. That cutoff is good for keeping the graph small, but for the further instrumentation I don't want to leave out any ops. More tomorrow.
/be
| Reporter | ||
Updated•17 years ago
|
Attachment #305955 -
Attachment is patch: false
Attachment #305955 -
Attachment mime type: text/plain → image/png
Comment on attachment 305953 [details] [diff] [review]
un-bitrot JS_OPMETER
r=shaver
Attachment #305953 -
Flags: review?(shaver) → review+
| Reporter | ||
Comment 58•17 years ago
|
||
Going to check in some #ifdef'ed off by default in debug and release builds metering, no one panic.
/be
Keywords: meta
| Reporter | ||
Updated•17 years ago
|
Attachment #305953 -
Flags: approval1.9b4?
Attachment #305953 -
Flags: approval1.9+
Comment 59•17 years ago
|
||
Comment on attachment 305953 [details] [diff] [review]
un-bitrot JS_OPMETER
a1.9b4=beltzner
Attachment #305953 -
Flags: approval1.9b4? → approval1.9b4+
| Reporter | ||
Comment 60•17 years ago
|
||
JS_OPMETER unrotted:
js/src/jsinterp.c 3.449
js/src/jsopcode.c 3.296
js/src/jsopcode.h 3.60
/be
Comment 61•17 years ago
|
||
Fixed?
| Reporter | ||
Comment 62•17 years ago
|
||
Beltzner: meta, this bug is a keeper. Any reason it got on your radar?
/be
Target Milestone: mozilla1.9alpha1 → ---
Comment 63•17 years ago
|
||
Probably because it has a approval1.9b4+ patch, but isn't resolved.
Comment 64•17 years ago
|
||
Comment on attachment 305953 [details] [diff] [review]
un-bitrot JS_OPMETER
Clearing approval flags, since this has landed but the bug remains open.
Attachment #305953 -
Flags: approval1.9b4+
Attachment #305953 -
Flags: approval1.9+
| Assignee | ||
Comment 65•17 years ago
|
||
I did some new measurements with Sunspider with a different output format. My format shows the pairs ranked by frequency. The first number is the fraction of all pairs represented by this line. The second number is the total so far at this line.
There are only 938 that appear. Given that amount, could we consider just implementing all of them as superops?
Of course, there is also the issue of triplets and longer sequences.
If we want to do triplets, and also if we don't want all 938 pairs, I think the best approach is to record the entire opcode stream, and use standard AI search algorithms to find a superop set that minimizes some metric. Ultimately we'd like to it be the total time taken, but we probably want to start the search with something faster to compute, like
(q1 * #of instructions executed) - (q2 * #of superops encoded)
where q1 and q2 are magic constants. We could even base this on a performance model derived from some initial tests.
I guess there must be prior work in this area. I found one paper [1] in a couple minutes. Do we have docs or code for the TT superinstruction selection procedure?
[1] http://www.cs.nuim.ie/~jpower/Research/Papers/2004/esa04.pdf
Also, what other test suites should I be using?
| Reporter | ||
Comment 66•17 years ago
|
||
The graph attached in comment 56 gives some idea of common sequences of various short lengths.
You can see the benchmark-ish getvar;uint16;lt;ifeq group for the (i < CONSTANT) condition of a hot loop or loops, probably a for loop -- which should jump to a test at the bottom and so use ifne instead of ifeq (bug 371802, I should split this out into a new bug and close that one) -- also the lt and ifeq should be fused into iflt (bug 363534).
The ifeq could be due to a hot if (i < CONSTANT) ... statement, too.
It would be interesting to get pure SunSpider results, but I think we also want some kind of aggregate for real-world browsing -- hence my running in-browser SS + gmail + opening bugzilla links from gmail.
We almost certainly don't want hundreds of super-ops. We might do away with some "sub-ops" that never occur alone. The prime example is pop after set (bug 312354).
Graydon or Steven knows about TT superword selection.
/be
Comment 67•17 years ago
|
||
Adding Vladimir Rainish (recent addition to Tamarin team at Adobe), who is starting an investigation into improving TT superword selection via profile-guided feedback.
Comment 68•17 years ago
|
||
good section on superoperator selection in this paper.
http://citeseer.ist.psu.edu/hoogerbrugge99code.html
also see many works by M. Anton Ertl on static and dynamic superinstructions for gforth and vmgen.
| Assignee | ||
Comment 69•17 years ago
|
||
Here is a list of the top JSOP sequences for saving dispatches on Sunspider. The attachment contains an explanation of the numbers.
I should also note that in Sunspider there are some very common, very long operation sequences. For example, replacing each of the 418240 dynamic occurrences of "getvar int8 rsh dup2 getelem one getvar int8 bitand lsh bitnot bitand setelem pop getvar getvar add setvar pop goto" with a single op would save 5% of dispatches. I don't imagine we'd want to do such a thing, but this information may bear on some decision, like inline threading. And it bodes well for tracing.
| Reporter | ||
Comment 70•16 years ago
|
||
Dave, maybe you should take this tracker bug. Feel free, if you agree.
/be
Priority: P1 → P2
| Reporter | ||
Comment 71•15 years ago
|
||
Only two bugs left, unless someone gets ambitious. I'm gifting this to dmandelin as suggested in comment 70.
Nick, see Dave's attachment 327040 [details] and prior. This relates to the peephole optimizer idea, maybe.
/be
Assignee: brendan → dmandelin
Updated•13 years ago
|
Status: ASSIGNED → RESOLVED
Closed: 13 years ago
Resolution: --- → WONTFIX
You need to log in
before you can comment on or make changes to this bug.
Description
•