Closed
Bug 661304
Opened 13 years ago
Closed 12 years ago
Not discarding images that are not visible on the current tab causes a memory usage problem
Categories
(Core :: Graphics: ImageLib, defect)
Core
Graphics: ImageLib
Tracking
()
RESOLVED
FIXED
mozilla22
People
(Reporter: jrmuizel, Assigned: jrmuizel)
References
(Blocks 1 open bug)
Details
(Keywords: regression, Whiteboard: [MemShrink:P1] fixed by bug 689623)
In Firefox 4 we stopped discarding images in the current tab that weren't visible. This can cause a lot more peak memory to be used.
This means we'll have to decode as we scroll, right?
| Assignee | ||
Comment 2•13 years ago
|
||
An example of where this is a problem is on a page like http://www.theatlantic.com/infocus/ which has lots of big images, but they are not all in view.
Comment 3•13 years ago
|
||
As part of bug 435296, we explicitly chose to discard images only if they were in background tabs. (This might have happened in a sub-bug, but if it was I wasn't able to find it.)
Initially, we did not lock images from the foreground tab into memory, which means that if you're scrolling up or down into an image that has been discarded, as the image is progressively decoded it'll "flicker" into view. (Dolske explicitly filed bug 516320 on mitigating this flicker.)
In 3.6 and prior, back to and including 3.0, we discarded images on the foreground frame, but redecoding these discarded images was synchronous. This meant you didn't get any flicker, but you also hung the browser for as long as it took to decode the image.
Comment 4•13 years ago
|
||
Maybe consider a middle-ground: decode images in view and also those within a page up/down or so and discard those outside of this range. This way big pages with lots of images don't hit as hard and if you're scrolling/paging up/down there's an extra buffer of ready images and an extra bit of time to asynchronously load the next screen's worth without noticing.
OS: Mac OS X → All
Hardware: x86 → All
Comment 5•13 years ago
|
||
Comment 4 was one of the early possible suggestions by Justin in bug 516320, but apparently bug 590252 and bug 590260 were considered to resolve the issue.
Comment 6•13 years ago
|
||
We've certainly got a lot of tugging between memory and responsiveness on this issue. When I landed all this code last august, the consensus was that we'd take the memory hit on the active tab in exchange for responsiveness and eliminating the flicker.
The ideal solution would be to lock/unlock images as they scroll in and out of view. But according to roc, this is pretty hard. Somebody's welcome to take it on though.
Comment 7•13 years ago
|
||
Random thought: this seems like it could be a Very Hard Problem for the general case, but maybe we could get away with just handling the special case of a page with a simple sequence of large images?
Basic idea:
1) Enable discarding on active tab
2) Keep an array of images on the page with size > X
3) Whenever an image in the array is painted, decode it and the next N too.
Obviously there's some handwaving in #2. :) But again, just the simple case (akin to onload="array = getElementsByTagName('img')") might be good enough?
Also, does Fennec do/want anything in this area? I'd think they have similar concerns with wanting to have bits just beyond the edge of the screen ready to go so that panning is smooth and checkerboardless.
Comment 8•13 years ago
|
||
(In reply to comment #7)
> Also, does Fennec do/want anything in this area? I'd think they have similar
> concerns with wanting to have bits just beyond the edge of the screen ready
> to go so that panning is smooth and checkerboardless.
True, but I have been watching this bug for the memory issues more than responsiveness issues. It's certainly a balancing act.
Comment 9•13 years ago
|
||
I thought romaxa had enabled full decode-on-draw for Fennec?
Comment 10•13 years ago
|
||
Bug 660577 shows we're getting a ton of complaints about the memory increase. I can understand the desire to reduce flickering, but if it causes paging that locks up the browser for 30 seconds at a time, or causes OOM aborts, that's worse than flickering.
Comment 11•13 years ago
|
||
We could discard on the active tab only when there's memory pressure (after discarding everywhere else). Seems like that would be an easy 90% solution.
Comment 12•13 years ago
|
||
(In reply to comment #11)
> We could discard on the active tab only when there's memory pressure
How do you gauge memory pressure?
Comment 13•13 years ago
|
||
We have no way to tell when we're paging or close to hitting OOM?
Comment 14•13 years ago
|
||
Does discarding currently consider the image size in any way? It's been a long time, but I vaguely recall part of the problem was that all various little images used on a page (like non-CSS rounded borders) would flicker into view, which is part of why it was so bad. If we only discarded "large" images, maybe that would help.
Actually, I think it was more about the decode-on-draw part of things than the discarding... (Like I said, it's been a while.) It made the experience of loading the page and immediately scrolling down rather odd.
Are there prefs (or simple patches?) to change how these things work wrt the active tab, so we can see again what the current state of things is?
Comment 15•13 years ago
|
||
(In reply to comment #13)
> We have no way to tell when we're paging or close to hitting OOM?
Not that I know of. It's a hard problem in general. cjones might know more.
Comment 16•13 years ago
|
||
We currently synchronously redecode images that are of size image.mem.max_bytes_for_sync_decode or lower, as a rough proxy for "will this image take a while to redecode?" This makes the scrolling flickering that Dolske is talking about in comment 14 less painful. (This value could also be tuned more if we had more data.)
Comment 17•13 years ago
|
||
(In reply to comment #12)
> (In reply to comment #11)
> > We could discard on the active tab only when there's memory pressure
>
> How do you gauge memory pressure?
Don't we have the memory pressure notification?
http://mxr.mozilla.org/mozilla-central/search?string=memory-pressure
Comment 18•13 years ago
|
||
(In reply to comment #16)
> This makes the scrolling flickering
> that Dolske is talking about in comment 14 less painful.
To clarify, under the current "lock-the-images-in-the-active-tab" strategy we use for, we never run into scrolling flickering. So these parameters are set up mitigate the flicker when switching tabs. There's nothing to mitigate for the scrolling case.
If we weren't locking the active tab, they would also mitigate flickering while scrolling. We might be doing something like that on mobile, but I can't remember.
Comment 19•13 years ago
|
||
> Don't we have the memory pressure notification?
As you note from that mxr search, it's not ever dispatched in normal operation except maybe on Fennec.
Comment 20•13 years ago
|
||
There must be some way for us to tell that we're running low on memory other than "reasonably-sized malloc's are failing".
Comment 21•13 years ago
|
||
There sure is. "Kernel sent us SIGTERM from the OOM killer" on Linux, for example.
That said, what are you trying to detect running low on? Address space for your process? Free pages in the kernel's VM system? Something else?
As far as I can tell from unscientific skimming of bug reports, our most common OOM crash scenario is running out of address space on 32-bit Windows builds. We can clearly "fix" this by going to 64-bit builds...
It seems that "keep decoded images around until memory pressure" is a heuristic pretty much guaranteed to yield bad UX on pages with too many image bits to fit in free RAM. That sounds likely to work well on common pages though.
The approach of comment 4 sounds pretty good. The multi-process rendering code we added for fennec gives us another weapon for better responsiveness: we can keep pre-rendered pixels in the UI process that can be scrolled "instantly", which allows us to tolerate long-ish rerenders from the content process. That area, slightly larger than the screen/window, is called the "displayport". Full decode-on-draw is an extreme way to restrict image memory usage to visible images, but not great because it always increases rerender latency and can waste CPU cycles (i.e. can hurt battery life).
Here's a strawman proposal for the (hopefully near) multi-process future
- Immediately scroll prerendered content in the UI process for quick response. Fennec already does this.
- In the content process, keep a cache of decoded images, only for the active/visible tab.
- When rerendering in content, ensure images within the displayport are decoded. They may already be in the cache. Set an "active" bit on them.
- After rerendering, discard all decoded images in the cache that don't have the "active" bit set.
- Finally, clear the "active" bit on all images in the cache.
This gives us a fuzzy weak sort-of-bound on how much memory we would allocate for decoded images. (It'd be trivially easy for web pages to break the "bound" and DoS themselves in this scheme, say by creating a huge number of translucent images stacked on top of each other.) This also ignores the problem of partial decoding of huge images, but I think that could be made to work in this plan.
Thoughts?
I don't think I have any ideas for the single-process case that haven't already been proposed somewhere.
(In reply to comment #6)
> The ideal solution would be to lock/unlock images as they scroll in and out
> of view. But according to roc, this is pretty hard. Somebody's welcome to
> take it on though.
It's not trivial, but it's definitely doable. If this is needed to significantly reduce our memory footprint, then let's do it!
Actually, just locking and unlocking images that change from visible to invisible or vice versa would be easy. But I think you want something more sophisticated, like "lock images that are within a certain distance of the viewport".
I think that combined with comment #22 could work for the single-process case. For example we could say "keep the viewport, and one page worth's of images above and below the viewport."
(In reply to comment #23)
> (In reply to comment #6)
> > The ideal solution would be to lock/unlock images as they scroll in and out
> > of view. But according to roc, this is pretty hard. Somebody's welcome to
> > take it on though.
>
> It's not trivial, but it's definitely doable. If this is needed to
> significantly reduce our memory footprint, then let's do it!
And if it doesn't significantly regress responsiveness.
Comment 26•13 years ago
|
||
Just to clarify:
- Judging from comment 3, this change was motivated by a desire to do more things asynchronously, is that right?
- How much work does the bholley/cjones/roc solution require, roughly? It'd be nice to fix this properly, but if it'll take a long time I wonder if there's a quick hack to address the memory usage problems.
I see that I just restated comments #4 and #5 and a whole lot of history. Sorry!
It's hard to predict how much work the above solution(s) would require.
Consider the "hard case" of scrolling down a large page full of huge JPEGs. If you have more than one core, I think you'd clearly want off-main-thread image decoding for optimal results. If you only have a (slow) single core, then I think the best we can do for smooth scrolling --- without decoding all the images ahead of time --- would be to ensure that we never block the main thread on decoding an entire image at once. That would mean either having a way to decode part of an image on the main thread and then yielding, or decoding whole images off the main thread and "decoding ahead" so that an image is fully decoded before we need to draw the first chunk of it.
Given that the single-core case is getting rarer and rarer, the off-main-thread image decoding approach sounds good to me.
Another thing we could try is decoding JPEG up to the YUV stage (which uses half the memory of RGB) and then decode-on-draw from YUV to RGB. That can be done very efficiently on a GPU, and even in software I expect it's not too bad (can be SIMD-optimized pretty well). The nice thing about this approach is that we would halve memory usage for decoded JPEGs across the board, even for visible images. Interesting and non-trivial project, but would combine nicely with the other solutions discussed here.
Comment 29•13 years ago
|
||
All image decoding, including redecoding, is asynchronous, and tries to spend at most image.mem.max_ms_before_yield ms decoding (we send at most image.mem.decode_bytes_at_a_time bytes to the decoder, then measure the amount of time we spent in the decoder; if it's greater than our max, we yield). In response to comment 26, yes, this yielding/asynchronousness is what leads to the "flickering".
Decoding images to YUV and then decoding-on-draw to RGB, potentially on the GPU, is very attractive, but colour management throws monkey wrenches in the gears. We'd either have to pre-correct to sRGB, and use sRGB textures, or implement colour management in shaders, either of which is a lot of work.
IMHO multi-process gives a framework in which we can make better tradeoffs here, including (actually) parallel image decoding/drawing to screen, and the code is already mostly there.
To make OOM crashes go away in the short term, single-process, what's the simplest thing we can do? Does anyone have data on percentage of windows users on 32-bit vs. 64-bit machines? Would having more address space eliminate 80% of the crashes?
Comment 31•13 years ago
|
||
cjones, it's not just OOM aborts that's the problem. People are also getting lots of paging because of this bug.
Comment 32•13 years ago
|
||
(In reply to comment #12)
> > We could discard on the active tab only when there's memory pressure
>
> How do you gauge memory pressure?
By the time we get nuked by the OOM killer, or malloc fails, it may be
too late to recover.
Can't we monitor the hard page fault rate for the process over the past
N seconds, and make some judgement based on that? ISTR at least SunOS/Solaris
could provide such information to user space.
Comment 33•13 years ago
|
||
It appears the fault count is available in /proc on Linux.
http://linux.die.net/man/5/proc
Comment 34•13 years ago
|
||
And there's getrusage() on Unix.
Comment 35•13 years ago
|
||
And about to use a weak reference list to this images and something like a GC to collect then and free then when some water mark is reached ?
| Assignee | ||
Updated•13 years ago
|
Keywords: regression
Comment 36•13 years ago
|
||
I've filed bug 664291 on generating better low-memory notifications.
| Assignee | ||
Comment 37•13 years ago
|
||
For what it's worth, it seems like Chrome just does a synchronous decode on draw to avoid this problem. I haven't yet looked at how they do discarding.
Updated•13 years ago
|
Whiteboard: [MemShrink]
Updated•13 years ago
|
Blocks: image-suck
Comment 39•13 years ago
|
||
The webpage http://www.gcforum.org/viewthread.php?tid=5721, with abundant images, freezes my firefox every time i try to view, and it exhausts my physical ram and virtual memory. This is truly unacceptable, here we have a browser can't handle large amount of images.
Updated•13 years ago
|
Assignee: nobody → jmuizelaar
Whiteboard: [MemShrink] → [MemShrink:P1]
Comment 40•13 years ago
|
||
(In reply to toughstrong from comment #39)
> The webpage http://www.gcforum.org/viewthread.php?tid=5721, with abundant
> images, freezes my firefox every time i try to view, and it exhausts my
> physical ram and virtual memory.
I can confirm this behavior with latest nightly on Windows XP.
Comment 43•13 years ago
|
||
This bug is causing me crashes on pages with a lot of big images (I have 2GB memory).
I think "MemShrink:P1" bugs like this one, that are known to cause actual crashes should have higher priority over other "MemShrink:P1" bugs , and be fixed sooner.
I think it should have the crash keyword.
Whoever has the permission, can you add the crash keyword, and therefore also change its Importance field from normal to critical ?
According to the field descriptions (I guess the Severity field was change to Importance, and the field descriptions document was not updated)
"Severity
This field describes the impact of a bug.
...
critical crashes, loss of data, severe memory leak"
Updated•13 years ago
|
Severity: normal → critical
Comment 44•13 years ago
|
||
Can't you just create for the time being as a temporary and fast solution a simple cache for decoded images for the current active tab , with a maximum size in bytes that will be (for example) 10 times the memory needed for the screen resolution ?
The cache can be simple with LRU (Least recently used) heuristics, which throws out the least recently used images when it fill up, and a new image needs to be added to the cache. Later, you can improve the heuristics as you desire to be better and more complicated.
For example, if the screen resolution is 1366X768 and 3 bytes are needed for each pixel in an RGB representation (I am not sure what is the decoded image representation, I just assume here it needs 3 bytes), then 1366X768X3 bytes are needed which is about 3MB for the screen resolution, or just about 30MB for a cache that can hold the images for 10 "screen pages" full of images for a typical screen.
That will be a major improvement over the current unacceptable situation where heavy images pages take up 1-2GB and halt Firefox to a crawl or make it out of memory.
I believe that will be good enough for most cases, and a fast to implement temporary solution.
Later, the heuristics can be improved, and implement loading of images that are predicted to be viewed , to the decoded images cache.
Comment 45•13 years ago
|
||
AFAICT the basic problem here is a lack of manpower. ImageLib is, unfortunately, more or less unmaintained right now. The graphics team is focused, for better or worse, on things like Azure and WebGL.
Implementing the cache isn't hard, the problem is that imagelib has no idea what images are on the screen and what images are not. Layout needs to tell imagelib that before imagelib can do anything smarter. This is bug 689623.
Comment 47•13 years ago
|
||
Speaking as the imagelib module owner, I can't think of much, feature-wise, that has wanted for resources on our side. As Kyle said, this is currently blocked on the layout/content side.
Comment 48•13 years ago
|
||
(In reply to Kyle Huey [:khuey] (khuey@mozilla.com) from comment #46)
> Implementing the cache isn't hard, the problem is that imagelib has no idea
> what images are on the screen and what images are not. Layout needs to tell
> imagelib that before imagelib can do anything smarter. This is bug 689623.
I don't think that layout or content need to tell imagelib what images are on the screen for the simple cache I suggested. These heuristics can be added later.
I am not familiar with the design/architecture of Firefox, and I don't know who manages the decoded images cache (is it imagelib or layout/content? ), but as I see it I think layout/content need to ask the cache or imagelib for the image when they need it for display (when it is on the screen), and imagelib, if it manages the cache, or the cache, if it is managed by layout/content, need to load the image to the cache if it is not there, and throw out the oldest used images (LRU cache - Least Recently Used) in the cache if there is images memory size in the cache becomes greater than the max cache size.
(In reply to nivtwig from comment #48)
> I think layout/content need to ask the cache or imagelib for
> the image when they need it for display (when it is on the screen)
Yes, that's exactly what *doesn't* happen now. Layout/content ask for all the images on the current tab, regardless of what is and is not on the screen. This is what bug 689623 will fix ...
Comment 50•13 years ago
|
||
> Speaking as the imagelib module owner, I can't think of much, feature-wise,
> that has wanted for resources on our side.
IIRC both jst and jrmuizel said that lack of imagelib resources was a problem, and they both said they'd talk to JP about hiring some additional manpower to help there. Maybe I misinterpreted the conversations.
From a MemShrink POV, imagelib is a problem point. E.g. see bug 683284 and all the bugs that block it. (Many of them are relevant to project Snappy too, even if they aren't marked as such.) In the six months since MemShrink started the only image image-related improvements that I can remember happening were (a) reducing the timeout for discarding decoded images in background tabs, and (b) turning on decode-on-draw. Both of those were just patches that flipped existing preferences.
I fully admit I know very little about imagelib and related parts of Firefox. But these are the perceptions I have at this point. I'd be more than happy for you to explain to me what I'm failing to see!
Comment 51•13 years ago
|
||
(In reply to Nicholas Nethercote [:njn] from comment #50)
> > Speaking as the imagelib module owner, I can't think of much, feature-wise,
> > that has wanted for resources on our side.
>
> IIRC both jst and jrmuizel said that lack of imagelib resources was a
> problem, and they both said they'd talk to JP about hiring some additional
> manpower to help there. Maybe I misinterpreted the conversations.
Oh, I did not mean to imply we don't have resource-related issues. In particular, we have a lot of technical debt and a roadmap to fix it (at least in Jeff's and my head) that doesn't really have anyone devoted to implementing it. But technical debt is not the same as features, as I elaborate below.
> From a MemShrink POV, imagelib is a problem point. E.g. see bug 683284 and
> all the bugs that block it. (Many of them are relevant to project Snappy
> too, even if they aren't marked as such.)
The most important bug there is this one (and its fennec duplicate, bug 691169). They both depend on the layout/content bug 689623. Similarly, snappy bug 689411 also depends on bug 689623. Other than those previously mentioned, there aren't any bugs on that dependency list that I'd prioritize above working on technical debt on imagelib. That's what I mean by there not being "much feature-wise, that has wanted for resources on our side."
If I'm wrong, please let me know!
> In the six months since MemShrink
> started the only image image-related improvements that I can remember
> happening were (a) reducing the timeout for discarding decoded images in
> background tabs, and (b) turning on decode-on-draw. Both of those were just
> patches that flipped existing preferences.
There are several bugs that make substantial improvements but which never landed for various reasons: Bug 683290, bug 685516, bug 683286.
Comment 52•13 years ago
|
||
> Other than those previously
> mentioned, there aren't any bugs on that dependency list
*without patches*
Comment 53•13 years ago
|
||
> There are several bugs that make substantial improvements but which never
> landed for various reasons: Bug 683290, bug 685516, bug 683286.
Bug 683286 wasn't marked with the MemShrink tag; I just added it. Its landing was just waiting for the next dev cycle, I've asked in the bug for jrmuizel to land it ASAP.
Bug 685516 sounds useful and ready to land now that Fennec is not multi-process, though it's not a MemShrink bug.
Bug 683290 is important for MemShrink, but its status is unclear to me.
> The most important bug there is this one (and its fennec duplicate, bug
> 691169). They both depend on the layout/content bug 689623. Similarly,
> snappy bug 689411 also depends on bug 689623.
Good to know, I've added a MemShrink tag to bug 689623.
> Other than those previously
> mentioned, there aren't any bugs on that dependency list that I'd prioritize
> above working on technical debt on imagelib. That's what I mean by there not
> being "much feature-wise, that has wanted for resources on our side."
I can believe that working on technical debt is more important than working on features at the moment. But you said yourself no-one's working on technical debt either!
So while I got the specifics wrong, the broader problem of "imagelib doesn't have anyone working on it" remains, AFAICT. What will happen if/when bug 689623 is fixed -- will someone be able to work on bug 691169 and bug 689623?
Comment 54•13 years ago
|
||
(In reply to Nicholas Nethercote [:njn] from comment #53)
> So while I got the specifics wrong, the broader problem of "imagelib doesn't
> have anyone working on it" remains, AFAICT. What will happen if/when bug
> 689623 is fixed -- will someone be able to work on bug 691169 and bug 689623?
I think you meant bug 689169 and bug 661304 here. The answer is "yes" no matter what—I will be coming off a major Azure-related project, and Jeff may be around, and we also have a new hire who we intend to be tasked with imagelib things.
Also, I've talked with Jet, and he knows how important bug 689623 is, and he's going to make sure it's worked on soonish.
Comment 55•13 years ago
|
||
(In reply to Joe Drew (:JOEDREW!) (Away Dec 17–Jan 2) from comment #54)
> I think you meant bug 689169 and ....
"NTP service not running on some build hardware"? Really?
Comment 56•13 years ago
|
||
Is all of this caching really necessary?
From what I checked, JPEG decoding time for desktop screen size images seem to be fast enough in most cases.
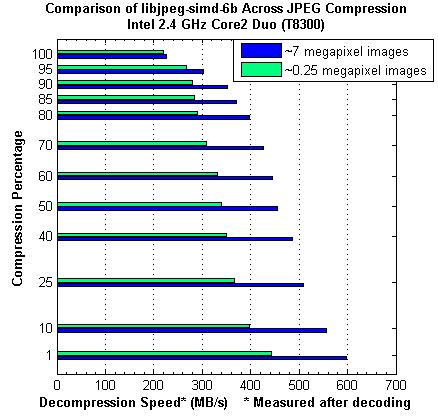
According to http://www.briancbecker.com/blog/2010/analysis-of-jpeg-decoding-speeds/ and http://www.briancbecker.com/blog/wp-content/uploads/2010/01/jpgcomparisonafter3.jpg (image from the same page),
JPEG decompression speeds are about 300MB/s (I selected a typical average), measured after decoding, on an Intel 2.4GHZ Core2 Duo.
Therefore if we assume a typical desktop screen, with resolutions of 1-2 Mega pixels, 2M pixels for HD, then the uncompressed image size is 6MB, assuming 3 bytes per pixel for RGB.
Therefore, with 300MB/s uncompression speed, a 6MB uncompressed image will uncompress in 20ms, or 50 images per second.
A 5M pixel camera image, 15MB uncompressed size, will uncompress in 50ms , or 20 images per second.
For comparison, If you use the keys for scrolling, the fastest character repeat time setting of windows is 30ms .
Therefore a full screen JPEG image decompression time should be less than the key repeat rate, or scrolling time. Even 5M pixel images should be able to fully display and scroll 20 images or screens per second, which seems to me to be very fast.
Therefore, maybe the quick and easy temporary solution is that there should be an about:config option/preference to allow always decode on draw (and not cache), also in the current tab, not just the background tabs as the decodeondraw option behaves currently.
Some notes:
1. The JPEG library used in the article was libjpeg-simd-6b, which was the fastest of the libraries (A port of the popular libjpeg to use modern SSE processor instructions by optimizing the core routines in assembly language). Mozilla's library may not be that fast. Nevertheless, it shows that JPEG decoding can be fast enough, therefore
2. This is only about JPEG decoding speed. Other image formats need to checked, they might be slower, but in my opinion JPEG is the typical scenario for large images and pictures on web pages.
3. Slowness in decoding is less meaningful now according to comment #3 because decoding is done asynchronously (in parallel). Therefore as I understand, even if decoding is slow, the scrolling will continue without a noticeable wait (if the user pressed the key/mouse), even if the full picture didn't show up yet.
4. The flickering problem was improved according to comment #3
{kind=link}
Comment 57•13 years ago
|
||
(In reply to Justin Dolske [:Dolske] from comment #55)
> (In reply to Joe Drew (:JOEDREW!) (Away Dec 17–Jan 2) from comment #54)
>
> > I think you meant bug 689169 and ....
>
> "NTP service not running on some build hardware"? Really?
bug 691169
Comment 58•13 years ago
|
||
(In reply to nivtwig from comment #56)
> A 5M pixel camera image, 15MB uncompressed size, will uncompress in 50ms ,
> or 20 images per second.
Well, the image at http://www.viruscomix.com/page560.html is about 6 megapixels (1056px × 5921px, 4899618 bytes compressed), but when I put the tab into the background, hit "Minimize memory usage" in about:memory and switch back to it it takes somewhere between 0.5 and 1 second to re-decode the image. That's very noticable if you switch to the tab - and that's on a Core i7 860 with 2.7GHz...
Also, it's a progressive JPEG image, but contrary to the download the re-decoding process doesn't progressively show the image being decoded which IMHO makes the pause seem even longer.
Comment 59•13 years ago
|
||
Modern camera images are 10MP, not 5MP. Decoded images are RGBA, so about 40MB. Even at 300MB/s, that's 130ms or so.
In practice, I've never seen your 300MB/s number hit even on a fairly modern laptop, to say nothing of phones.
One more note: you assume paints happen at the key repeat rate, which is not true even for scrolling with smooth scrolling and the like. And also not true with the (fairly common) case of animation over an image background. In practice, right now we paint about once every 10ms or so... (that's a bug; it should be once every 16ms).
Eventually, with decoding work spread over an increasing number of CPU and GPU cores, JPEG always decoding on draw will be fast enough on non-mobile devices. But we're not there yet and it may never be the power-efficient solution.
Comment 61•13 years ago
|
||
(In reply to Boris Zbarsky (:bz) from comment #59)
> Modern camera images are 10MP, not 5MP. Decoded images are RGBA, so about
> 40MB. Even at 300MB/s, that's 130ms or so.
>
> In practice, I've never seen your 300MB/s number hit even on a fairly modern
> laptop, to say nothing of phones.
1. The 300MB/s number is not my number, it is from an independent blogger. Let's assume it is wrong.
Then what are the numbers that you have seen for Firefox?
Is there any link to a benchmark of Mozilla's imagelib or JPEG decoding speed ?
2. On a second thought, I don't think that the fastest PageUP/PageDown key repeat rate (30ms) is the correct threshold to consider . I think the correct threshold to look at is the human (eye?) perception of how much time is noticeable and considered too slow for the image to appear, once scrolling was stopped at a certain screen of the page, or when switching to a different tab.
I think this threshold is higher, someting like 50-100ms, not 30ms, but I can't be sure, this needs testing or human interface expert advice. I think that the scrolling can continue without images appearing at every key repeat (30ms), or scrolling can be slowed down somewhat to 20 pages per second (50ms) and the images fully appearing, without the user noticing that the scrolling is not at the fastest key repeat rate.
3. The 10MP image problem can be overcome by setting a threshold for decode on drawing only fast to decode images.
There can be a preference like "decodeondraw_fast_decoding_images", which when enabled will only decode on draw (and not cache) images that are expected to be fast enough to decode by a certain criteria that should be defined. The main parameter here is the number of image pixels, but also cpu speed or benchmark score, adjustment for number of cores, and screen size (the expected decode time of the image should be adjusted to screen size to take into account the worst case where all of the screen is full of other images).
If the expected decoding time of the image (adjusted to screen size) is less than the eye perception "slowness threshold", then the image should not be cached, only decoded on draw.
For example, if a typical (or worst case, if desired) decoding speed is determined to be lets say 80MB/s , and the human perception of "slowness" in image appearance is 60ms, then all images up to 1M pixels can be decoded on draw and not cached, and all images above that should be cached decoded. A 1Mp is 4MB uncompressed , which can be estimated beforehand to be decoded in 50ms or so (or 60ms including waiting for the paint event, according to your comment?) at a decoding speed of 80MB/s .
This can be a big memory win on most web pages. For example, most of the images in the sample problematic page given above, http://www.theatlantic.com/infocus/ , are below that threshold and therefore will not be kept in memory !
If 1Mp is too high, you can set it at 0.5Mp or any other value, which will not cache all images up to 800X600 .
This filtering of which images need to be cached by their "fastness to decode", is simple, and will be useful not just as a temporary solution but also later, when the planned caching of images by their proximity to the viewport (instead of all the images in the active tab) will be implemented , because even then, there might not be a need to cache small, fast to decode images.
4. As the image library decode performance is improved, the "base predetermined speed" (80MB/s) can be raised, and more images will be below the threshold, and therefore not need to be cached.
5. The "base speed" can be predetermined, or calibrated for the performance of the current actual processor by a calibration routine that runs once as Firefox starts to measures it.
Comment 62•13 years ago
|
||
(In reply to Kurt Pruenner from comment #58)
> (In reply to nivtwig from comment #56)
> > A 5M pixel camera image, 15MB uncompressed size, will uncompress in 50ms ,
> > or 20 images per second.
>
> Well, the image at http://www.viruscomix.com/page560.html is about 6
> megapixels (1056px × 5921px, 4899618 bytes compressed), but when I put the
> tab into the background, hit "Minimize memory usage" in about:memory and
> switch back to it it takes somewhere between 0.5 and 1 second to re-decode
> the image. That's very noticable if you switch to the tab - and that's on a
> Core i7 860 with 2.7GHz...
>
> Also, it's a progressive JPEG image, but contrary to the download the
> re-decoding process doesn't progressively show the image being decoded which
> IMHO makes the pause seem even longer.
1) This image may be (or may not be) a special case, covered in bug 435628.
I found bug 435628 on a similar issue. I am not too knowledgeable about the matter but as I understand from what I read, the bug says that Progressive JPEGs are very slow to decode when gfx.color_management.enabled=true . From the bug:"Image takes up to 1000% (10x) longer to load than with gfx.color_management.enabled=false".
From what I understand, since then, there is no gfx.color_management.enabled option in about:config, since this option was removed (and is always true), and it always does color management when there is v2 color management profile in the image.
Now there is only gfx.color_management.enablev4 option which defaults to false, but using color management for v2 is enabled always, so your image might be slow to decode because of this bug. Correct me if I misunderstood.
2) See in comment #61, especially comment 3 : There can be a threshold, for example 1M pixels for doing decodeondraw. In this case, your image will be held in cache since it is 6Mp, and there will be no performance problem.
3) As you said, contrary to the download the re-decoding process doesn't progressively show the image being decoded which makes the pause seem even longer.
I downloaded the images in your page (Using Tools->"Page Info"->Media, then selecting and saving all images), and used Windows photo viewer to scroll through all those images in a directory. The progressive blurred representation of the image shows up immediately as you scroll, so its decoding time should is very fast. Therefore if Firefox showed the blurred image at the first phase of the progressive JPEG, it would show up immediately, and the it will later take 1-2 seconds to completely decode the image. (That is in case we don't cache the image as suggested in comment 2)
| Assignee | ||
Comment 63•13 years ago
|
||
(In reply to nivtwig from comment #61)
> (In reply to Boris Zbarsky (:bz) from comment #59)
> > Modern camera images are 10MP, not 5MP. Decoded images are RGBA, so about
> > 40MB. Even at 300MB/s, that's 130ms or so.
> >
> > In practice, I've never seen your 300MB/s number hit even on a fairly modern
> > laptop, to say nothing of phones.
>
>
> 1. The 300MB/s number is not my number, it is from an independent blogger.
> Let's assume it is wrong.
> Then what are the numbers that you have seen for Firefox?
> Is there any link to a benchmark of Mozilla's imagelib or JPEG decoding
> speed ?
Average JPEG decoding speed on FF9 on OS X is about 8-11MB/s
Comment 64•13 years ago
|
||
(In reply to Jeff Muizelaar [:jrmuizel] from comment #63)
>
> Average JPEG decoding speed on FF9 on OS X is about 8-11MB/s
1) What processor does this MAC OSX have?
2) Is that decoding speed measured in compressed or uncompressed bytes?
Note that I was talking about decompression speed measured after decoding in uncompressed bytes. (We can talk also about uncompressed pixels, if you prefer).
See the link I gave earlier:
http://www.briancbecker.com/blog/wp-content/uploads/2010/01/jpgcomparisonafter3.jpg
3) Here is another link for performance benchmarks for libjpeg-turbo, the jpeg library Firefox moved to (from libjpeg), as I understand. Open it in OpenOffice Calc spreadsheet -
http://www.libjpeg-turbo.org/pmwiki/uploads/About/libjpegturbovsipp.ods
(The spreadsheet is linked from http://www.libjpeg-turbo.org/About/Performance)
All the performance numbers there are in Megapixels/sec. You should look at the rows/lines "Decomp. perf" .
For the first system (the Dell 2.8GHZ P4), in all of the images there the decoding speeds are higher than 28M pixels/s (if I am not mistaken). From a quick look it seems that most of the images and test systems (not just the first, the Dell) achieve higher than 40M pixels/s, including Mac Systems.
So, a 1M pixel image threshold as I suggested will take at most 30ms for decompression, if these numbers are correct.
Comment 65•13 years ago
|
||
> I think the correct threshold to look at is the human (eye?) perception
Humans can easily tell the difference between 30fps and 60fps scrolling, apparently.
> setting a threshold for decode on drawing only fast to decode images.
There's no point. Those images are small and don't take much memory anyway. It's the big images that are a problem!
Comment 66•13 years ago
|
||
(In reply to Boris Zbarsky (:bz) from comment #65)
> > setting a threshold for decode on drawing only fast to decode images.
>
> There's no point. Those images are small and don't take much memory anyway.
> It's the big images that are a problem!
Also, we already have something much like this — image.mem.max_bytes_for_sync_decode — below this source size, we do a synchronous decode, and above this, asynchronous.
Comment 67•13 years ago
|
||
The discussion about decoder speeds may be on to something, but it doesn't belong in this bug. I've filed bug 715919. Let's please continue this discussion there.
Comment 68•13 years ago
|
||
If images are discarded when they're scrolled out of the way, would this also help with bug 395260 ?
Comment 69•13 years ago
|
||
(In reply to Jeff Muizelaar [:jrmuizel] from comment #0)
> In Firefox 4 we stopped discarding images in the current tab that weren't
> visible. This can cause a lot more peak memory to be used.
Are images created using something like "new Image().src = url" considered "in the current tab"? As described in bug 683286, these images are currently being decoded so when/if they are being freed is a current issue until that bug is fixed. Also see my variation on this question at bug 683286 comment 10.
Comment 70•13 years ago
|
||
On a related note, Bug 659220 (marked duplicate of bug 660577 which was marked duplicate of meta bug 683284) raised a question that I don't see in the remaining live bugs on image consumption.
Specifically bug 659220 raised the question that even through DOM/JS image objects are small, the images they are holding on to may be large. Since they are small they may not trigger a JS GC very quickly, possibly leaving the layout layer thinking those images are still in use. This would apply for all the cases where an image object could be orphaned like "new Image" and removeChild(). Does the layout layer catch these cases and release the image, or does it wait for JS to actually release the objects? In the same vein, does it catch a img.src = null (sorry if that is a redundant question with bug 683286 comment 10 - seemed good to have it here for completeness).
Comment 71•12 years ago
|
||
As a frustrated user, whose 512 MB RAM computer has died of OOM several times because of FF, let me add a few observations and suggestions, for what they're worth:
- Regardless of the amount of free RAM (meaning "unused" + "used for file cache"), allocating more than the total amount of RAM is definitely a bad idea. FF 10.0.5 esr on linux does that.
- I haven't read the code, so please correct if I'm wrong, but I guess that images are decoded in parallel, and the decoding step uses much more memory than needed to store the result: on a badly designed web page, that has <img>.srcs to twenty 3000x2000 1MB jpeg images, scaled down to 300x200, the decoding/rendering phase eats all my RAM. When I'm lucky and OOM kills syslog (ahem...) instead of my X session, I see FF's memory footprint go down abruptly after images are rendered, and stay low also when I scroll down to expose all the images within a few seconds. Perhaps it would be better to limit the parallelism: there is not much point in having 20 decoding threads on a single cpu core.
- On a computer with lots of swap space, triggering a moving garbage collection is one of the worst things you can do when you know you were substantially swapped out: a lot of pages that were harmlessly sleeping in the swap file must be faulted back in physical memory and partially rewritten to newly allocated pages, causing a storm of random reads from the disk, and making the machine unresponsive for a long time. I don't know what type of GC is implemented in FF.
- I like the idea of a bound on the memory cache for decoded images. Another possibility is to store them to the filesystem, and let the operating system's page-cache layer do the caching: when there's lot of free RAM, the images are almost guaranteed to be in RAM when they are needed, but FF doesn't have to explicitly manage the cache, because the kernel will purge it when needed, and I bet it knows better than FF when RAM is running short.
Comment 72•12 years ago
|
||
> twenty 3000x2000 1MB jpeg images, scaled down to 300x200
Scaling doesn't affect decoded image size. So a page like you describe would currently use 20 * 3000 * 2000 * 4 = 480,000,000 bytes.
However in the specific case of X we store the decoded images on the X server, so it's _possible_ that there is an intermediate period there when they're in both the X process memory and our process memory. So if we do have lots of threads going for the decode it's also possible that that could happen for multiple images at once...
> I don't know what type of GC is implemented in FF.
It's not a moving GC, but like most GCs it has a tendency to touch most of the JS heap anyway.
> when there's lot of free RAM, the images are almost guaranteed to be in RAM when they
> are needed
Unfortunately, some OSes are not as aggressive as Linux about page-caching disk. :(
Comment 73•12 years ago
|
||
(In reply to Boris Zbarsky (:bz) from comment #72)
> Scaling doesn't affect decoded image size. So a page like you describe
> would currently use 20 * 3000 * 2000 * 4 = 480,000,000 bytes.
Scaling doesn't affect decoded image size, but it affects the size of pixmaps that have to be kept around to redisplay the page at any moment. From your words, I understand that FF delegates the scaling to X, probably for performance reasons. But the cost is huge, on pages like the one I mentioned.
> However in the specific case of X we store the decoded images on the X
> server, so it's _possible_ that there is an intermediate period there when
> they're in both the X process memory and our process memory. So if we do
> have lots of threads going for the decode it's also possible that that could
> happen for multiple images at once...
>
Yes, the crowd of decoding threads is a problem in itself. Especially since FF considers invalid an image that could not be decoded because its decoding thread could not allocate memory: if one wraps FF in a script that sets ulimit -v to a reasonable value before launching the executable, AND is lucky enough that mmap2() failures happen where they are handled and don't kill the program, perhaps the browser manages to display the page with a few placeholders for broken images, but thereafter marks the images as permanently broken, so that they can't be displayed even when one navigates to a different, nice page that includes only one of those images.
Comment 74•12 years ago
|
||
We have a long list of image bugs, and the MemShrink team has been trying to get the resources to fix them for six months now. I'm as frustrated as you are.
Comment 77•12 years ago
|
||
Hi.
is this bug fixed at all?
I find it dissapointing we had dev's saying its easy but nothing has been done? I would have thought this should take priority over adding new features to the browser.
Images flickering into view is far preferable to run away memory usage, also even on 3.6 I never really noticed flickering, was that only a problem on slow machines?
Comment 78•12 years ago
|
||
As you can see from the dependency, this bug requires bug 689623 before it can be fixed, and bug 689623 seems to be moving closer to completion.
Comment 79•12 years ago
|
||
Chris, the "easy" thing was tried and caused a terrible user experience when switching tabs (think multi-second hangs while images are decoded). So it turned out not to be workable, unfortunately.
Comment 81•12 years ago
|
||
Bug 689623's patches has fixed this -- decoded images that are sufficiently far from the viewport are discarded after ~10 seconds. See bug 689623 comment 155 for more details.
Status: NEW → RESOLVED
Closed: 12 years ago
Resolution: --- → FIXED
Updated•12 years ago
|
Whiteboard: [MemShrink:P1] → [MemShrink:P1] fixed by bug 689623
Target Milestone: --- → mozilla22
Updated•12 years ago
|
relnote-firefox:
--- → ?
Updated•12 years ago
|
Comment 82•12 years ago
|
||
This bug has been listed as part of the Aurora 22 release notes in either [1], [2], or both. If you find any of the information or wording incorrect in the notes, please email release-mgmt@mozilla.com asap. Thanks!
[1] https://www.mozilla.org/en-US/firefox/22.0a2/auroranotes/
[2] https://www.mozilla.org/en-US/mobile/22.0a2/auroranotes/
Updated•11 years ago
|
relnote-firefox:
22+ → ---
You need to log in
before you can comment on or make changes to this bug.
Description
•