Closed
Bug 1243585
Opened 9 years ago
Closed 9 years ago
(telemetry v3) Periodically attempt to re-upload Telemetry documents that failed to upload
Categories
(Firefox for Android Graveyard :: General, defect)
Tracking
(firefox49 fixed)
RESOLVED
FIXED
Firefox 49
| Tracking | Status | |
|---|---|---|
| firefox49 | --- | fixed |
People
(Reporter: mcomella, Assigned: mcomella)
References
Details
Attachments
(16 files)
|
(deleted),
image/jpeg
|
Details | |
|
(deleted),
text/x-review-board-request
|
sebastian
:
review+
|
Details |
|
(deleted),
text/x-review-board-request
|
sebastian
:
review+
|
Details |
|
(deleted),
text/x-review-board-request
|
sebastian
:
review+
|
Details |
|
(deleted),
text/x-review-board-request
|
sebastian
:
review+
|
Details |
|
(deleted),
text/x-review-board-request
|
sebastian
:
review+
|
Details |
|
(deleted),
text/x-review-board-request
|
sebastian
:
review+
|
Details |
|
(deleted),
text/x-review-board-request
|
sebastian
:
review+
|
Details |
|
(deleted),
text/x-review-board-request
|
sebastian
:
review+
|
Details |
|
(deleted),
text/x-review-board-request
|
sebastian
:
review+
|
Details |
|
(deleted),
text/x-review-board-request
|
sebastian
:
review+
|
Details |
|
(deleted),
text/x-review-board-request
|
sebastian
:
review+
|
Details |
|
MozReview Request: Bug 1243585 - Rename JSONFilePingStore -> TelemetryJSONFilePingStore. r=sebastian
(deleted),
text/x-review-board-request
|
sebastian
:
review+
|
Details |
|
(deleted),
text/x-review-board-request
|
sebastian
:
review+
|
Details |
|
(deleted),
text/x-review-board-request
|
sebastian
:
review+
|
Details |
|
(deleted),
text/x-review-board-request
|
sebastian
:
review+
|
Details |
We must do this to ensure the server receives at least one of each document we have attempted to upload. This is important to do before documents have counts since the previous upload in order to ensure we have an accurate measurement of the counts.
Since we can successfully upload a document but have our upload Service killed before we can respond to the success (i.e. reset the counts), we have to save the document for upload and reset the counts in a transaction. This document will be stored on disk and this periodic service can attempt to upload any documents it finds stored on disk.
| Assignee | ||
Updated•9 years ago
|
Summary: Periodically attempt to re-upload Telemetry documents that failed to upload → (telemetry v3) Periodically attempt to re-upload Telemetry documents that failed to upload
| Assignee | ||
Updated•9 years ago
|
Assignee: nobody → michael.l.comella
| Assignee | ||
Updated•9 years ago
|
Blocks: ut-android
Updated•9 years ago
|
| Assignee | ||
Comment 1•9 years ago
|
||
Design proposal (see attached for sketch):
Fennec will construct a telemetry ping via the TelemetryPingBuilder (bug 1247489). It will call...
TelemetryStore.queueCorePing, which will atomically 1) add any counts in the store [1] to the builder, 2) store the ping, and 3) reset these counts. During this operation, the Store will manage clean-up operations [2]. Then the store will call...
TelemetryScheduler.notifyQueuedCorePing. The scheduler can decide when/what to upload based on existing conditions [3]. In the case of the core ping, we want to upload immediately, always, so it starts...
TelemetryUploadService with ACTION_UPLOAD_CORE_PING [4]. For now, this action will upload all queued core pings [5]. On failure, it does nothing. On success, it will notify...
TelemetryStore with which items are successfully uploaded so they can be removed from the Store.
Remaining unknown: storage. Should we store entries into the DB, DB + sharedPrefs, or JSON + shared preferences? This decision affects many other unknowns, e.g. handling concurrency & transactions on the store.
After I think through this, I'll come up with a storage proposal.
Notes:
* For simplicity, I've ignored bandwidth considerations. The Scheduler should be flexible enough to incorporate them.
* The scheduler is not fleshed out. In my head, it could work well if each ping type is handled separately but I'm afraid it will become complex if we expect to coordinate between multiple ping types.
* These function names are not final.
Richard, thoughts?
[1]: e.g. session times; Fennec will add to the TelemetryStore over-time through methods like Store.incrementCoreSessionCount();
[2]: e.g. for storage considerations, if the store contains more than 10 core pings, delete until it has 10.
[3]: e.g. current network connection, were pings recently uploaded, number of queued pings.
[4]: The parameters passed to the intent service by the scheduler can decide if it should upload (e.g. not on wifi) and what it should upload (e.g. only upload 2 pings to save data).
[5]: It's ideal to batch uploads for battery life reasons – it takes time to enable/disable the radio. I'm currently not considering network concerns.
Flags: needinfo?(rnewman)
Comment 2•9 years ago
|
||
You have to figure this one out for yourself, I'm afraid. I trust you and the rest of the team.
Flags: needinfo?(rnewman)
| Assignee | ||
Comment 3•9 years ago
|
||
Sebastian, do you mind giving comment 1 an architecture review?
Flags: needinfo?(s.kaspari)
Comment 4•9 years ago
|
||
-- Architecture
Your architecture looks good! I would consider adding an additional layer in front of the store and the scheduler. Just to make those components dumb and just focused on what they should do (e.g. Why should the Store talk to the Scheduler). Something like this:
Fennec --(with: PingBuilder) --> TelemetryController --> Store
|
`---> Scheduler
The TelemetryController (It's the first name I came up with..) adds the ping to the store and makes decisions like "Is the store now full enough to schedule background work?". Does this make sense?
-- Scheduling
I wish we would have a minSdkVersion of 16 (Jelly Bean) and we could use JobScheduler[1]. It would make your life easier here because it can handle things like: "Only run this task if there's a network connection. Retry if this failed. I just want to do this on WiFi".
I recently filed bug 1248901 to write a helper class that uses JobScheduler where available and uses a very limited AlarmManager-based approach on ICS. I would like to have it for DLC and content notifications too. Some GSoC students have been interested in picking this up.
Apart from that I'd like to collect more arguments for minSdkVersion 16 and post this to the mailing list soon. With 2.2% of users [2] we might be able to ditch ICS too soon.
[1] http://developer.android.com/reference/android/app/job/JobScheduler.html
[2] http://developer.android.com/training/basics/supporting-devices/platforms.html
-- Storage
If it's just a dump storage and you do not use query magic then I'd go an use a flat file. That's what I do for the catalog of downloadable content:
https://dxr.mozilla.org/mozilla-central/source/mobile/android/base/java/org/mozilla/gecko/dlc/catalog/DownloadContentCatalog.java
The implementation is heavily inspired by SharedPreferencesImpl:
http://grepcode.com/file/repository.grepcode.com/java/ext/com.google.android/android/5.1.1_r1/android/app/SharedPreferencesImpl.java/
Another thing you might want to look at is Jake Wharton's DiskLruCache (based on the memory LRU cache that comes with Android):
https://github.com/JakeWharton/DiskLruCache
You might not need the library but the code could be interesting to you and food for thought. It uses flat files and a journal file to make sense of them. What's interesting about that is that it doesn't need to replace items but just stores new items and updates the journal. Every now and then it compacts the data.
Flags: needinfo?(s.kaspari)
Comment 5•9 years ago
|
||
(In reply to Sebastian Kaspari (:sebastian) from comment #4)
> I wish we would have a minSdkVersion of 16 (Jelly Bean) and we could use
> JobScheduler[1]. It would make your life easier here because it can handle
> things like: "Only run this task if there's a network connection. Retry if
> this failed. I just want to do this on WiFi".
Aside: Let's start a list of things that would be easier if we dropped ICS. We still have a decent numbers of users on it, so it's not an obvious choice right now, but at some point it will be worth it.
| Assignee | ||
Comment 6•9 years ago
|
||
(In reply to Sebastian Kaspari (:sebastian) from comment #4)
> Just to make those components dumb and
> just focused on what they should do (e.g. Why should the Store talk to the
> Scheduler). Something like this:
>
> Fennec --(with: PingBuilder) --> TelemetryController --> Store
> |
> `---> Scheduler
My approach was to make the components linear and as simple as possible:
Fennec -(PingBuilder)-> Store -> Scheduler -(if ready)-> UploadService
It makes sense for the Store to talk to the Scheduler if you consider the Store as the single source of truth who tells everyone when there's an update (push, rather than pull). However, I didn't consider the coupling between the Store & Scheduler. My proposal would be for the Store to alert the Scheduler using the observer pattern.
There is some precedence here – flux follows a linear data flow and has the store directly talk to the view. Funnily enough, it does this via the observer pattern.
I concerned the Controller adds a layer of indirection that makes the architecture harder to follow. I think this is the MVC vs. flux discussion, however I haven't wrapped my head fully around them yet to really understand.
> I wish we would have a minSdkVersion of 16 (Jelly Bean) and we could use
> JobScheduler[1].
Unfortunately, JobScheduler is API 21.
> I recently filed bug 1248901 to write a helper class that uses JobScheduler
> where available and uses a very limited AlarmManager-based approach on ICS.
A JobScheduler-like API sounds like it could be really useful – I didn't consider it in my approach.
That being said, my Scheduler is pretty empty atm and can be filled in with anything so I don't think it should change the architecture I proposed.
| Assignee | ||
Comment 7•9 years ago
|
||
I chose SQL. My data:
* A list of TelemetryPing (uniquely incrementing id + server + payload) queued for upload
* A series of key/value pairs specific to the ping, known as "counts" (note: some of these are running values that get zeroed for the next telemetry ping):
- ping sequence number
- searches: list of `searchEngine -> # of searches`
- usage time counts: two separate ints (# of sessions & time in sessions)
The type of data stored in the counts could change in the future.
My requirements for the data:
1) Atomically increment seq. number, zero the running counts, and append a ping to the list (i.e. we don't want to have two pings with the same seq. number or double-count the running counts)
2) Maintain a list of pings to upload
3) Prune ping list by insertion order (i.e. uniquely incrementing ID) or date – e.g. maximum 20 items. This can occur on append.
4) Atomically remove pings by ID (i.e. we mark upload success for each ping ID individually and remove only those that were successful)
5) Increment the counts at any point in the application (e.g. made a search)
6) ? Handle concurrent access (e.g. UploadService may not be on the same thread as our background thread)
In order to make 1) atomic, it is my understanding they all need to be in the same file, ruling out mixed file approaches (e.g. JSON files for pings & shared preferences for counts). For flat file storage, in order to increment the counts at any point (5), we'll have to read the entire file, update the counts, and rewrite it, which is likely to be expensive. In my understanding of SQL, it can read & update the specific part of the file directly, which would likely be less expensive. This is going to be the biggest use of storage (e.g. every time we search via the search engine) so I chose SQL. A similar situation arises when deleting pings by ID.
My proposed schema has two tables:
counts
----------
| key | val |
-----------
| str | # |
...
pings
----------------------------
| id | server-info | payload |
----------------------------
| # | str | str |
...
I'd propose a different storage location for different pings types (e.g. if we pushed main pings into the DB here, it could cause excessive fragmentation if we upload main pings less frequently, for example, only on wifi). Additionally, these could have different storage solutions based on ping type (e.g. I believe the main ping is already created by gecko so we don't have to worry about atomic seq. number increments with ping storage so we can store these in flat files).
My concern with SQL is the hidden complexity (i.e. [1]). To address some of these:
* I'd expect Android to solve some of the per device issues (e.g. Android sets reasonable defaults for the device)
* We're storing the telemetry pings which are large strings (200+ bytes) directly into the DB, which can be slow. However, [2] (explaining blobs, but I believe is handled the same as text data) shows that data less than 20k in size is faster in the DB and our strings are much smaller
* Since we attempt upload all of our queued TelemetryPings at once, I expect the pings table to often be empty and fragmentation to be less of an issue.
Other notes:
* From [1], it sounds like inserts into the counts table (e.g. key-value pairs) can interlace the data between the two tables so we'll still need to vacuum.
Sebastian, do you have any thoughts?
[1]: https://wiki.mozilla.org/Performance/Avoid_SQLite_In_Your_Next_Firefox_Feature
[2]: https://www.sqlite.org/intern-v-extern-blob.html
Flags: needinfo?(s.kaspari)
| Assignee | ||
Comment 8•9 years ago
|
||
Some unanswered questions on my end:
* When should we vacuum?
* Is it too expensive to update counts on the background thread? e.g. everytime we search, we block the background thread to write. [1]
* How big (by file size or item count) should we let the DB grow before pruning it? 20 items (~4kb)? 40 items (~8kb)?
* How can I make this API generic enough to make it easy to add additional ping types?
[1]: Presumably the UI thread won't wait on the background thread so it shouldn't be a problem? It'd suck if the process is killed though. :P
Comment 9•9 years ago
|
||
(In reply to Michael Comella (:mcomella) from comment #6)
> My proposal would be for the Store to alert
> the Scheduler using the observer pattern.
Sounds good. I think both implementations are not far away from each other: I'm proposing something like a write-through class that forwards the write to the store and does scheduling afterwards. Your proposal writes to the store and then triggers code that does the scheduling afterwards.
(In reply to Michael Comella (:mcomella) from comment #6)
> There is some precedence here – flux follows a linear data flow and has the
> store directly talk to the view. Funnily enough, it does this via the
> observer pattern.
Obviously I need to do some follow-up reading on flux. :) But what's the idea behind it? "This is what flux does" is somehow unsatisfactory.
(In reply to Michael Comella (:mcomella) from comment #6)
> I concerned the Controller adds a layer of indirection that makes the
> architecture harder to follow.
I often feel exactly the opposite: It's not always easy to understand what's happening if you need to follow the observers - which is sometimes a bit inconvenient in an IDE. It seems like there will always ever be only one observer here. Do we win something by adding this additional layer of abstraction?
(In reply to Michael Comella (:mcomella) from comment #7)
> Sebastian, do you have any thoughts?
Okay, let me try to challenge your design. Not necessarily to propose a better solution but to validate/discuss some of your points.
(In reply to Michael Comella (:mcomella) from comment #7)
> [..] in order to increment the counts at any point (5), we'll have to read
> the entire file, update the counts, and rewrite it, which is likely to be
> expensive.
Do you really have to? You have to record that something incremented a count, but you do not need the result now.
With a journal based implementation you can use a single file and only append data/events to it (without reading). You can even invalidate/reset previous data without rewriting the file (See [1] for inspiration).
In a sense your design is storing the data at the time of recording in a way that is optimized for the consumer (background service) that is running at a later time. We are sending (actually storing) telemetry everywhere in our app. This should affect the "regular" app code as little as possible. The background service is talking to the network, so additionally work to compact/generate the data doesn't add much. With a smart scheduler this can even run at a time where the device hasn't much to do anyways.
No doubt SQLite is optimized. I wonder if it can beat a "file append" though. FWIW under the hood SQLite uses journals too. However with your own journal you are in control about at what time the data is read/compacted.
You could even optimize writes away by keeping the data in memory for some time. But this introduces the possibility of data loss. Something we probably do not want here. However keeping the data in the memory for a short amount of time will allow you to write bigger chunks and limit disk access.
Undoubtedly a journal based implementation is costlier and requires a high test coverage.
[1] https://github.com/JakeWharton/DiskLruCache/blob/master/src/main/java/com/jakewharton/disklrucache/DiskLruCache.java#L103-L139
[2] https://www.sqlite.org/fileio.html#tocentry_246
---
What are your thoughts on threading? Regardless of the storage we want to have the operation off the calling thread asap and in a cheap way. As telemetry is send/stored rather frequently my first intention is to use a Looper[1]/HandlerThread[2] based approach an pass messages[3] to it. Is this something you'd add to the store? I think a layer in front of the store could be helpful here and isolate that.
[1] http://developer.android.com/reference/android/os/Looper.html
[2] http://developer.android.com/reference/android/os/HandlerThread.html
[3] http://developer.android.com/reference/android/os/Message.html
(In reply to Michael Comella (:mcomella) from comment #8)
> * When should we vacuum?
Do you mean removing obsolete pings - after or before upload? If before: Is this something we expect to do regularly or is the expected behavior to upload everything? In both cases it sounds like something the background service should do and not interfer with the app.
> * Is it too expensive to update counts on the background thread? e.g.
> everytime we search, we block the background thread to write. [1]
I'd use a dedicated thread for telemetry. Then I don't think we do not need to worry about blocking anything else.
> * How big (by file size or item count) should we let the DB grow before
> pruning it? 20 items (~4kb)? 40 items (~8kb)?
Don't be too conservative here. This is super small compared to all the other stuff we store locally. Can we try to upload before pruning? It seems like getting the data is more worth than saving some local kilobytes.
Flags: needinfo?(s.kaspari)
Comment 10•9 years ago
|
||
(In reply to Michael Comella (:mcomella) from comment #7)
> I chose SQL. My data:
> * A list of TelemetryPing (uniquely incrementing id + server + payload)
> queued for upload
> * A series of key/value pairs specific to the ping, known as "counts"
> (note: some of these are running values that get zeroed for the next
> telemetry ping):
> - ping sequence number
> - searches: list of `searchEngine -> # of searches`
> - usage time counts: two separate ints (# of sessions & time in sessions)
Just curious, since you didn't really talk about why SQL was better:
* Why would we need two tables?
* Why wouldn't we just build pings as we normally would, archiving them fully if we need to delay sending?
* Do we need a separate system for the sequences, I mean different than the non-archiving system? If we weren't archiving you'd need to track seq, searches and usage anyway.
| Assignee | ||
Comment 11•9 years ago
|
||
After some more thinking, I've actually moved back to your design. Some pieces I was missing from my design:
* Who is going to initialize the Store? The Scheduler? (assuming they need to be initialized)
* Who manages dispatch to Store.store(PingBuilder) for different ping types? e.g. in my solution, this is handled by the developer in the Activity and there's no clear entry point to Telemetry:
Fennec -(CorePingBuilder)-> CorePingStore ...
|
----(MainPingBuilder)-> MainPingStore ...
My design would have to move this functionality elsewhere – the Activity, which is already bloated, or another class, e.g. a Controller.
(In reply to Sebastian Kaspari (:sebastian) from comment #9)
> > I concerned the Controller adds a layer of indirection that makes the
> > architecture harder to follow.
I realized what I was trying to accomplish was reduce the number of components in the system in an effort to reduce complexity, but I only pushed that functionality into another component (the Activity). Additionally, the component is less modular because its instantiation code is tied to the Activity.
> I often feel exactly the opposite: It's not always easy to understand what's
> happening if you need to follow the observers - which is sometimes a bit
> inconvenient in an IDE. It seems like there will always ever be only one
> observer here. Do we win something by adding this additional layer of
> abstraction?
I agree that it gets hard to follow.
I think there are different messages sent between the "Store -> observer" implementation and the "Store.store(); Scheduler.schedule();" (your suggested implementation):
* Store -> observer: indicates "new data has been saved". Anyone can listen.
* Store.store(); Scheduler.schedule();: more closely couples the store event to the schedule event
However, since we're not expecting to have additional observers, I agree that this message [1] is an added layer of abstraction for little gain (e.g. in theory, you could write observers for all method calls :P).
[1]: thinking out loud: Is this a signal? Is this connected with event streams? I haven't explored these ideas yet.
> I'm proposing something like a write-through class that forwards the write
> to the store and does scheduling afterwards.
I dislike how the "write-through" nature duplicates method names/signatures/etc. (e.g. to the Controller and then to the Store) but I can't think of something better (and I've probably spent too much time thinking! :P).
> Do you really have to? You have to record that something incremented a
> count, but you do not need the result now.
>
> With a journal based implementation you can use a single file and only
> append data/events to it (without reading). You can even invalidate/reset
> previous data without rewriting the file (See [1] for inspiration).
I didn't consider this – thanks for pointing this out!
> Undoubtedly a journal based implementation is costlier and requires a high
> test coverage.
I agree and, given the added complexities, I am inclined to go with SQL. In some sense, a journal-based implementation is also starting to inch (very, very!) slowly towards the functionality of SQL. :P
> What are your thoughts on threading?
Still thinking – I'll get back to you.
> (In reply to Michael Comella (:mcomella) from comment #8)
> > * When should we vacuum?
Vacuuming [1] is a process by which SQL defragments & compacts its data (note: deletions only flag for removal and don't actually change the size of the DB file). It does this by copying the DB to a new file. You can do vacuum on insert/removal/update (at some cost) or do it separately, but it's a long-running operation.
[1]: https://sqlite.org/lang_vacuum.html
> Do you mean removing obsolete pings - after or before upload?
As you point out, if we prune before upload, we may lose data, so we can do this after. I envision something like `Store.onUploadAttemptComplete(int[] ids)` handling this (which could get called even if the upload is not successful).
> In both cases it sounds like something the background
> service should do and not interfer with the app.
I think that depends on the results of the threading discussion. I'm afraid of making the UploadService do more than just upload.
> > * Is it too expensive to update counts on the background thread? e.g.
> > everytime we search, we block the background thread to write. [1]
>
> I'd use a dedicated thread for telemetry. Then I don't think we do not need
> to worry about blocking anything else.
This makes sense especially if we're concerned with telemetry ping data (specifically CorePing data) being recorded and uploaded ASAP. I'm concerned how spawning new threads could affect the application but I suppose we can cross that bridge if we start to see perf problems. It should be relatively easy to push this off to the background thread anyway.
> > * How big (by file size or item count) should we let the DB grow before
> > pruning it? 20 items (~4kb)? 40 items (~8kb)?
>
> Don't be too conservative here. This is super small compared to all the
> other stuff we store locally.
I'm concerned about slow creep – e.g. we store 4kb here, 4kb there, and soon enough we're storing a ton of data. I think it's better to start small – as a web browser, what are the chances that we're uploading 40 pings at once anyway? Maybe we should revisit this when we improve our offline content experience. ;)
---
> Obviously I need to do some follow-up reading on flux. :) But what's the
> idea behind it? "This is what flux does" is somehow unsatisfactory.
Disclaimer: I was conflating the theory of flux with the problem I saw here – I'll get to that at the end.
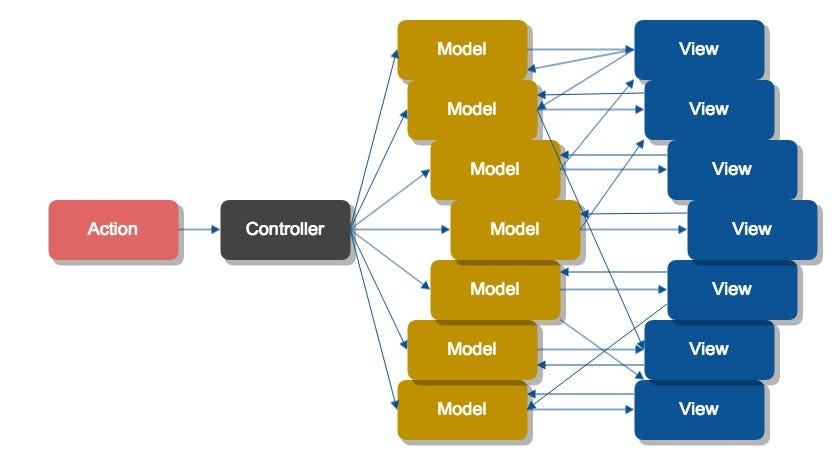
MVC and similar architecture patterns have a problem for large applications where an update to a model becomes difficult to reason about because an update from the model can cause an update in the view, which can update a model, which can update a view, etc. – the cascading side effects are difficult to understand: see [0]. The model talking to the view and vice versa is described as bidirectional data flow.
flux addresses this with a "unidirectional data flow" – see [1]. Essentially, all changes to the model have to come from new actions – view data doesn't trickle back up and you can think about your code as a series of actions (with their limited side effects) rather than a method call with a large number of side effects that make it unclear what occurred.
If you want to know more, their documentation (with the linked video) gives a pretty good overview of flux: https://facebook.github.io/flux/
Note: from what I can tell, flux has been largely supplanted by Redux, which also features a unidirectional flow. Several other frameworks also feature this unidirectional flow (e.g. Cycle.js).
Back to the telemetry problem, I conflated my architecture as the only way to do "unidirectional data flow" when in actuality, the similarity is just that they can both be written in a diagram with straight lines. In the Controller design, since the store doesn't cause any data/side-effects to cascade back into the controller, the data flow is actually unidirectional by nature.
The straight lines made it look simpler in diagram form too which tricked me into thinking it would be simpler. :P
In my original (straight-line) design:
* It's harder to see the bigger picture – you have to jump from class to class to get to the last method
* The code is entirely sequential (for better or worse)
* The high-level diagram is simpler and easier to understand
Whereas the controller outlines the high level (Store.store(); Scheduler.schedule();) much better in code. However, it creates some questions:
* Who handles the onUploadAttemptComplete? The Store or the Controller?
* Who handles recording new counts? The Controller or the Store? (in my design, it does a write-through in order to dispatch without the caller having to know which ping an event is in)
* Who handles the request from the UploadService to get the list of pings to upload? The Controller or the Store?
I think generally it makes sense to me to send everything through the Controller to simplify things but then it has a lot of responsibilities, which increases complexity. I
[0]: https://cdn-images-1.medium.com/max/2000/1*gSSDaoZsDB-dZGKqnVk1gQ.jpeg
[1]: https://facebook.github.io/flux/img/flux-simple-f8-diagram-with-client-action-1300w.png
---
Still TODO:
* Threading
* Should all of the data access go through the Controller? (e.g. updating counts, getting a list of pings to upload, removing pings by id)
* I realized I don't have a good way of accessing the Store from the UploadService. Some thoughts:
- Assuming the Controller (and the classes it instantiates, e.g. Store) don't contain any state we can't recreate via an Intent, we could create a new Controller in the UploadService and write to the store through that. This is likely the simplest but could break if state is added to the Controller.
- Pass in data through the intent (e.g. pings to upload) and use a file as secondary storage (e.g. save the list of ids successfully uploaded). However, the UploadService needs to know how to access this file so it adds some complications.
- Use a LocalBroadcastManager to communicate back to the Activity. This creates a tighter coupling to the Activity (e.g. having to add receivers to the Activity to interact with the Controller instance), causes a callback headache, and we won't be able to store the results if the Activity is killed.
- Bind the Service with the Activity
- Upload on a thread instead of a Service
{kind=link}
{kind=link}
| Assignee | ||
Comment 12•9 years ago
|
||
(In reply to Mark Finkle (:mfinkle) from comment #10)
> Just curious, since you didn't really talk about why SQL was better:
Sorry, I could have been clearer. From comment 7: "For flat file storage, in order to increment the counts at any point (5), we'll have to read the entire file, update the counts, and rewrite it, which is likely to be expensive. In my understanding of SQL, it can read & update the specific part of the file directly, which would likely be less expensive. This is going to be the biggest use of storage (e.g. every time we search via the search engine) so I chose SQL."
> * Why would we need two tables?
One table is to represent a list of pings to upload (i.e. the counts have already been stored) and another table is to represent several active counts (i.e. not present in any pings). You could put them into the same table (e.g. as a key-value store), but I don't see any reason to.
> * Why wouldn't we just build pings as we normally would, archiving them
> fully if we need to delay sending?
I'm not sure what you mean by "build pings as we normally would".
To try to answer, my current design creates a ping, saves it to the ping table, and the UploadService will try to upload everything in the ping table (if we always upload, this will always be one item).
I feel this is simpler than archiving fully *only* if we need to delay sending because:
* In the latter approach, on upload success, we have to reset the counts [1]. However, on upload failure, we have to reset the counts and store the ping. My approach simplifies this by maintaining one control flow: always reset the counts and store the ping.
* There is a single source of truth: the DB has a list of the pings to upload, rather than a ping being stored in memory somewhere
[1]: The counts being values that get zeroed each time a ping is sent like usage numbers
> * Do we need a separate system for the sequences, I mean different than the
> non-archiving system? If we weren't archiving you'd need to track seq,
> searches and usage anyway.
Since we need to reset these sequences (or counts as I've been calling them) atomically when storing a ping, it's my understanding that it needs to be the same system.
Comment 13•9 years ago
|
||
(In reply to Michael Comella (:mcomella) from comment #12)
> (In reply to Mark Finkle (:mfinkle) from comment #10)
> > Just curious, since you didn't really talk about why SQL was better:
>
> Sorry, I could have been clearer. From comment 7: "For flat file storage, in
> order to increment the counts at any point (5), we'll have to read the
> entire file, update the counts, and rewrite it, which is likely to be
> expensive. In my understanding of SQL, it can read & update the specific
> part of the file directly, which would likely be less expensive. This is
> going to be the biggest use of storage (e.g. every time we search via the
> search engine) so I chose SQL."
OK. Why would we make one flat file and not a JSON file for each ping. Essentially, why not just save the JSON we would have sent to the server to disk? Then send them later, without needing to touch the contents at all, when we retry?
| Assignee | ||
Comment 14•9 years ago
|
||
To address some TODOs:
> * I realized I don't have a good way of accessing the Store from the UploadService.
We can pass it through the Intent as a Parcelable (or get a new instance statically from elsewhere but passing in our dependencies is probably best). Note: the IntentService runs on a separate thread (which is good, since we probably shouldn't block recording counts on network calls!) which means the Store either needs locking or cannot contain mutable state (and it's currently the latter in my designs).
> * Should all of the data access go through the Controller?
To reduce responsibility of the Controller: No! The Controller can get getters for each of its Store instances. Thus, the current responsibilities of the Controller:
* Instantiate Store & Scheduler for each ping type and provide a getter to the Stores
* queue pings for upload (by writing & scheduling them)
Last TODO: threading.
By the way, thanks for these thorough design reviews! It's been really helpful for me to wrap my head around my designs and come up with a more optimal solution before I start coding and running into issues, like the one I discovered with my previous design.
| Assignee | ||
Comment 15•9 years ago
|
||
Sorry, I'm still leaving things out.
(In reply to Mark Finkle (:mfinkle) from comment #13)
> OK. Why would we make one flat file and not a JSON file for each ping.
> Essentially, why not just save the JSON we would have sent to the server to
> disk? Then send them later, without needing to touch the contents at all,
> when we retry?
To ensure we don't double count, we need to atomically add the counts to a ping, store the ping, and reset the counts. In order to be atomic, it is my understanding that we need to do this in one file.
If we weren't in one file, for example:
* Get counts & reset them on disk.
* Put retrieved counts into the ping in memory.
* Killed by Android – the ping is never saved to disk.
Comment 16•9 years ago
|
||
(In reply to Michael Comella (:mcomella) from comment #15)
> Sorry, I'm still leaving things out.
That's OK. I was trying to figure out the level of complexity/robustness we are trying to achieve, and I should have just asked up front. Without any spec or other guidance, you are working toward the most reliable, robust system you can create.
I think we need to ask ourselves what level of robustness we expect. I don't want to end up with another FHR client-side system. We don't need it for Telemetry, which has different server-side assumptions than FHR did.
>
> (In reply to Mark Finkle (:mfinkle) from comment #13)
> > OK. Why would we make one flat file and not a JSON file for each ping.
> > Essentially, why not just save the JSON we would have sent to the server to
> > disk? Then send them later, without needing to touch the contents at all,
> > when we retry?
>
> To ensure we don't double count, we need to atomically add the counts to a
> ping, store the ping, and reset the counts. In order to be atomic, it is my
> understanding that we need to do this in one file.
I don't think we do. If each ping created resets the counters, and each ping is then saved to a file, I don't see why we need a single file.
> If we weren't in one file, for example:
> * Get counts & reset them on disk.
> * Put retrieved counts into the ping in memory.
> * Killed by Android – the ping is never saved to disk.
We would only lose the data for one ping, right? This would include the data for one session. This would be bad if we were foreground killed. If we are background killed, and we write to disk on background, we'd potentially lose the data if we got killed very soon after getting backgrounded. Maybe a quick race.
These sound like similar issues we'd see from Gecko's UT pings too. They're probably within the realm of "good enough."
My point is: You have to balance the complexity and requirements. The more robust you hope to make a system, the harder it will be to get right, the longer it will take to get it shippable, and the more susceptible it will be to regressions.
Consider the implications of any plan you make.
Comment 17•9 years ago
|
||
(In reply to Michael Comella (:mcomella) from comment #11)
> but I can't think of something better (and I've probably spent too much time
> thinking! :P).
This is actually a good point. Thinking back none of my "whiteboard designs" made it into production unchanged. At the end of the day they need to fit into an already existing system. So nowadays I often start by writing code, right in the app. Not the actual implementation but empty methods with some todos to remind me what they should do, maybe passing some non-existing parameters around. Things like "Should this be an observer" are easy to test and change with that. At some point I start to implement some of the methods and maybe I realize that I need to refactor something to make it simpler/cleaner. Maybe it makes sense to do this here as well. This only works for the basic code architecture. You still might not know what the best storage solution is yet but you can define the interface you expect from it.
| Assignee | ||
Comment 18•9 years ago
|
||
(In reply to Mark Finkle (:mfinkle) from comment #16)
> I think we need to ask ourselves what level of robustness we expect. I don't
> want to end up with another FHR client-side system. We don't need it for
> Telemetry, which has different server-side assumptions than FHR did.
This is a fair point.
Using your approach from comment 16 [1], we could lose those counts if Android kills us. If we spawn a background thread, our Activity can close and in that case Android is more likely to kill us. However, this is a short running background operation called from onStart, so it's very unlikely that this would happen.
Given the current schema, the counts we could potentially lose are:
* Usage (time & count)
* Number of searches per engine
* Not all sequence numbers will be used
I don't think any are mission critical to get 100% right and I'm okay with the less robust solution [2], given the reduced complexity. However, I'm not the primary consumer of the data – Finkle or Margaret, can I get your opinion here?
fwiw, in the error case, instead of losing data, we could double count (i.e. reset counts after storing ping to disk) but I think it's safer to lose data because it's clearer to identify when something is going wrong and it's more modest.
[1]: we reset the counts, put the counts in a ping in memory, and then store the json payload in a flat file on a background thread
[2]: e.g. saving counts to SharedPrefs & the pings-to-upload to flat files rather than my more robust solution of storing everything in SQL to allow for atomic operations
Flags: needinfo?(mark.finkle)
Flags: needinfo?(margaret.leibovic)
| Assignee | ||
Comment 19•9 years ago
|
||
Review commit: https://reviewboard.mozilla.org/r/47491/diff/#index_header
See other reviews: https://reviewboard.mozilla.org/r/47491/
| Assignee | ||
Comment 20•9 years ago
|
||
Review commit: https://reviewboard.mozilla.org/r/47493/diff/#index_header
See other reviews: https://reviewboard.mozilla.org/r/47493/
| Assignee | ||
Comment 21•9 years ago
|
||
compile.
Review commit: https://reviewboard.mozilla.org/r/47495/diff/#index_header
See other reviews: https://reviewboard.mozilla.org/r/47495/
| Assignee | ||
Comment 22•9 years ago
|
||
Review commit: https://reviewboard.mozilla.org/r/47497/diff/#index_header
See other reviews: https://reviewboard.mozilla.org/r/47497/
| Assignee | ||
Comment 23•9 years ago
|
||
Programming with interfaces so these changesets will mostly stay static. Still TODO:
* TODOs in code
* Use PingBuilder & Dispatcher in Fennec code
* Flesh out UploadService
* (after unblocked) Write out PingStore
| Assignee | ||
Comment 24•9 years ago
|
||
Thoughts:
* An alternative design put this code in a CorePingUtil but I decided these
methods are tied closely to the TelemetryCorePingBuilder.
* Adding these methods makes it less clear what the class is about (without
filtering on public methods that is).
I'm not sure what the best trade-off is.
Review commit: https://reviewboard.mozilla.org/r/47869/diff/#index_header
See other reviews: https://reviewboard.mozilla.org/r/47869/
| Assignee | ||
Comment 25•9 years ago
|
||
Review commit: https://reviewboard.mozilla.org/r/47871/diff/#index_header
See other reviews: https://reviewboard.mozilla.org/r/47871/
| Assignee | ||
Comment 26•9 years ago
|
||
Review commit: https://reviewboard.mozilla.org/r/47873/diff/#index_header
See other reviews: https://reviewboard.mozilla.org/r/47873/
| Assignee | ||
Comment 27•9 years ago
|
||
Review commit: https://reviewboard.mozilla.org/r/47875/diff/#index_header
See other reviews: https://reviewboard.mozilla.org/r/47875/
| Assignee | ||
Comment 28•9 years ago
|
||
Comment on attachment 8742953 [details]
MozReview Request: Bug 1243585 - Create telemtry/core/ pkg and move files accordingly. r=sebastian
Review request updated; see interdiff: https://reviewboard.mozilla.org/r/47491/diff/1-2/
| Assignee | ||
Comment 29•9 years ago
|
||
Comment on attachment 8742954 [details]
MozReview Request: Bug 1243585 - Move Intent constants into UploadService. r=sebastian
Review request updated; see interdiff: https://reviewboard.mozilla.org/r/47493/diff/1-2/
| Assignee | ||
Comment 30•9 years ago
|
||
Comment on attachment 8742955 [details]
MozReview Request: Bug 1243585 - Add UploadAllPingsImmediatelyScheduler and tests. r=sebastian
Review request updated; see interdiff: https://reviewboard.mozilla.org/r/47495/diff/1-2/
| Assignee | ||
Comment 31•9 years ago
|
||
Comment on attachment 8742956 [details]
MozReview Request: Bug 1243585 - Add TelemetryDispatcher. r=sebastian
Review request updated; see interdiff: https://reviewboard.mozilla.org/r/47497/diff/1-2/
| Assignee | ||
Comment 32•9 years ago
|
||
Still TODO:
* (blocked) Write the Store
* Add some tests
Comment 33•9 years ago
|
||
(In reply to Michael Comella (:mcomella) from comment #18)
> (In reply to Mark Finkle (:mfinkle) from comment #16)
> > I think we need to ask ourselves what level of robustness we expect. I don't
> > want to end up with another FHR client-side system. We don't need it for
> > Telemetry, which has different server-side assumptions than FHR did.
>
> This is a fair point.
>
> Using your approach from comment 16 [1], we could lose those counts if
> Android kills us. If we spawn a background thread, our Activity can close
> and in that case Android is more likely to kill us. However, this is a short
> running background operation called from onStart, so it's very unlikely that
> this would happen.
>
> Given the current schema, the counts we could potentially lose are:
> * Usage (time & count)
> * Number of searches per engine
> * Not all sequence numbers will be used
>
> I don't think any are mission critical to get 100% right and I'm okay with
> the less robust solution [2], given the reduced complexity. However, I'm not
> the primary consumer of the data – Finkle or Margaret, can I get your
> opinion here?
Sorry it took me a while to get up to speed on what's going on in this bug.
As long as we understand the ways in which this data might not be 100% right, I'm fine with the tradeoff for a simpler system. I'd prefer to implement the simplest solution possible, see what the data looks like, and then decide if we should invest in more improvements from there.
I recognize that there might be a point at which the only way to improve the system is to throw it away and replace it with a more complex system, but let's cross that bridge when we get to it.
Flags: needinfo?(margaret.leibovic)
Comment 34•9 years ago
|
||
Brian Nicholson suggested running an analysis on gaps in seq numbers to see how many pings are being dropped. That should provide some insight into our reliability.
It does mean that we need to understand how and when seq number gaps can be created.
Flags: needinfo?(mark.finkle)
| Assignee | ||
Comment 35•9 years ago
|
||
Storage solution, take 2 (take 1 in comment 7):
Problem: I want to build a system that can:
1.1) Store counts & sequence number
1.2) Zero counts & increment sequence number
2.1) Store a list of pings to upload
2.2) Retrieve a list of all pings to upload
2.3) Remove successfully uploaded pings from list (but not all pings)
2.4) Can keep a maximum limit on number of pings (e.g. by size or by count)
My solution:
1) SharedPreferences for counts
+ Easy to use
+ Fast (in memory)
- Increased bloat in SP file for profile (though we're only adding a handful of counts)
- Hard to remove counts later (i.e. individual keys – we need bug 1045887 or similar)
2) Each ping to upload is stored in its own JSON file (influenced by Finkle) with `{server: ..., payload: ...}`. The IDs (i.e. to remove specific values) will be declared in the file name (e.g. "core_store_10.json").
+ Fast append
+ Easy to test (can just create files on disk without worrying about json contents)
+ Don't need to read payloads in order to prune (this is valuable since we want to prune after upload, at which point we don't care to read the ping payloads)
+ Fast removal (just flagged deleted on the filesystem)
+ Easy concurrency, given the data requirements (see below)
- Reading every ping is slow (i.e. have to read many files)
- File manipulation is typically annoying & verbose
- Have to maintain a file-name convention
When we want to store a ping, we will:
1) Read the counts from SP & store in-memory in Ping
2) Reset the counts in SP
3) Attempt to save ping.
We will attempt upload and then prune down the total number of pings (deleting the least recently stored). We do that in this order to prevent pruning pings we could have potentially uploaded (i.e. we want to upload as much as possible).
IntentService tasks run in sequence so we can only have concurrent access to the json store by:
* The IntentService is reading/writing
* Fennec is appending a new ping
If we make the append an atomic file operation, the IntentService can't read or act on it until it's done writing, fixing all of our concurrency issues (see below for SP concurrency question).
Notes:
* Document this: we could lose data if Android kills us after 2 but before 3, but this is highly unlikely. Note: we use this execution order to avoid double counting – rather I chose to lose data because 1) it's more modest and 2) it's easier to see when something is going wrong.
* Document this: we can see if ^ occurs by observing breaks in the sequence numbers. However, similar breaks can occur by being unable to upload pings for long periods of time and us pruning the file count
* Typically this un-uploaded list will be a handful of pings (2-3 on average, iirc, according to current beta trends) so practically speaking, the perf shouldn't matter too much.
* If we want to reduce storage requirements, we can move to csv
An alternative is to store all the pings to upload in one file but it's more complex: file locking, (if file format = each line is a separate JSON ping [1]) have to maintain special file format, and ensure there are no \n in the ping. It's worth noting this is likely to be faster than the multi-file solution (e.g. accessing all unuploaded pings is 1 disk seek).
Things I don't know:
1) How much unuploaded data do we want to store?
2) How does SharedPreferences handle concurrency? (...do we do this correctly in regular fennec code?)
3) Does Android have a maximum file node limit? What about per app?
NI Sebastian to look this over, but I'm fairly confident it'll work (yay simplicity!).
[1]: This can have better append perf than a valid json file, where we'll have to manipulate the json tokens (e.g. remove `}`, add `,`, append data, append `}`).
Flags: needinfo?(s.kaspari)
Comment 36•9 years ago
|
||
(In reply to Michael Comella (:mcomella) from comment #35)
> 1) SharedPreferences for counts
> - Hard to remove counts later (i.e. individual keys – we need bug 1045887
> or similar)
OFFTOPIC: I thought we already had this somewhere. I can only find the WhatsNewReceiver that listens for PACKAGE_REPLACED events. We should build something that receives those events and can do migrations (whatever is needed) from app version to app version. But this is not easy with our generated version codes. :)
> 2) Each ping to upload is stored in its own JSON file (influenced by Finkle)
> with `{server: ..., payload: ...}`. The IDs (i.e. to remove specific values)
> will be declared in the file name (e.g. "core_store_10.json").
10 is the sequence number?
> - Reading every ping is slow (i.e. have to read many files)
Compared with the time for the upload this should be negligible.
> - File manipulation is typically annoying & verbose
Yeah. And we should be aware that this can fail, e.g. half written files. We could try to make it atomic (e.g. AtomicFile) but there's no difference here between ignoring a broken ping file and a not successful atomic write. Even worse: backup files of atomic writes laying around.
> - Have to maintain a file-name convention
Luckily the "volatility" of the data makes it easy to change the convention later.
> IntentService tasks run in sequence so we can only have concurrent access to
> the json store by:
> * The IntentService is reading/writing
> * Fennec is appending a new ping
Is the IntentService or Fennec (e.g. the app "frontend") writing the ping to disk?
If Fennec is writing the ping: How do we prevent the service reading a file while it's being written?
If the service is writing the ping: At first I though that's quite an overhead to start the service but then again this has advantages:
* If only the service access the storage then concurrency is simple / not existing
* Android keeps the service alive if Intents keep incoming (less overhead)
* If things get killed then we might be able to ask Android to re-deliver the Intent (less lost data?)
> If we make the append an atomic file operation, the IntentService can't read
> or act on it until it's done writing, fixing all of our concurrency issues
> (see below for SP concurrency question).
Oh, you wrote exactly the same. I read everything before answering but somehow I missed that. :)
> 1) How much unuploaded data do we want to store?
* Do we have a problem with storage currently? Meaning: Do we know that user's complain that we use to much storage space? (-> Is this a problem we need to solve now)
* The ping data seems to be rather small compared to other things we store (favicons) (-> Is THIS the problem we need to fix if there's a storage problem)
* At the very least let's make this dependent on the available storage of the device: Throwing ping data away because it's more than x kB when there are GBs unused seems to be a bad optimization.
> 2) How does SharedPreferences handle concurrency? (...do we do this
> correctly in regular fennec code?)
Multithreading is no problem. Multiprocess is.
If you are curious (Interesting class in general):
https://android.googlesource.com/platform/frameworks/base/+/master/core/java/android/app/SharedPreferencesImpl.java
> 3) Does Android have a maximum file node limit? What about per app?
Oh very good point. I bet it does.
Flags: needinfo?(s.kaspari)
| Assignee | ||
Comment 37•9 years ago
|
||
(In reply to Sebastian Kaspari (:sebastian) from comment #36)
> > 1) SharedPreferences for counts
> > - Hard to remove counts later (i.e. individual keys – we need bug 1045887
> > or similar)
> We should build
> something that receives those events and can do migrations (whatever is
> needed) from app version to app version. But this is not easy with our
> generated version codes. :)
Alternatively, we could do SQLiteOpenHelper style upgrades and set the version numbers by hand (but that becomes the janitor service bug I linked).
> > 2) Each ping to upload is stored in its own JSON file (influenced by Finkle)
> > with `{server: ..., payload: ...}`. The IDs (i.e. to remove specific values)
> > will be declared in the file name (e.g. "core_store_10.json").
>
> 10 is the sequence number?
Yeah
> Compared with the time for the upload this should be negligible.
Nice observation!
> > - File manipulation is typically annoying & verbose
>
> Yeah. And we should be aware that this can fail, e.g. half written files.
Noted. /me thumbs up
> > IntentService tasks run in sequence so we can only have concurrent access to
> > the json store by:
> > * The IntentService is reading/writing
> > * Fennec is appending a new ping
>
> Is the IntentService or Fennec (e.g. the app "frontend") writing the ping to
> disk?
Fennec/the app "frontend"/the Store via the Dispatcher via Fennec. Currently this should occur on our background thread.
> If Fennec is writing the ping: How do we prevent the service reading a file
> while it's being written?
My intent was to use AtomicFile operations.
> If the service is writing the ping: At first I though that's quite an
> overhead to start the service but then again this has advantages:
> * If only the service access the storage then concurrency is simple / not
> existing
> * Android keeps the service alive if Intents keep incoming (less overhead)
But those are some compelling advantages. My one concern is that we're giving the UploadService more responsibilities/making it more complex, but at the same time, since we can specify explicit ACTIONs, this code should be sectioned off from one another.
I'll consider this approach. :)
> * If things get killed then we might be able to ask Android to re-deliver
> the Intent (less lost data?)
If we choose to redeliver the intent, we'd have to consider how redelivering an intent for upload happens, which starts to make this more complex. It's probably simpler to just drop the intents (though we're more likely to get killed in a service than in writing in fennec, hm...).
Also, I'm not sure how Android handles OOM with Intent redelivery – can it get into a crash loop if we always OOM?
| Assignee | ||
Comment 38•9 years ago
|
||
(In reply to Sebastian Kaspari (:sebastian) from comment #36)
> > 1) How much unuploaded data do we want to store?
>
> * Do we have a problem with storage currently? Meaning: Do we know that
> user's complain that we use to much storage space? (-> Is this a problem we
> need to solve now)
A few months ago, we were trying to get our APK below 20 MB and I suppose I've just assumed this to still be the case. I recognize the APK is different from the installed size but I don't think it's great to install and then expand rapidly in size, e.g. I actively uninstall apps I think are larger than they should be because with my photos and videos, I often run out of phone storage. I think it's easier and safer to be conservative now and up it later if it's a problem.
> * The ping data seems to be rather small compared to other things we store
> (favicons) (-> Is THIS the problem we need to fix if there's a storage
> problem)
That's true – there are bigger fish to fry.
But do we need to store a huge backlog of core pings? 40 or so seems reasonable to me. (however, maybe this will become more of an issue as we start to have more offline functionality)
> * At the very least let's make this dependent on the available storage of
> the device: Throwing ping data away because it's more than x kB when there
> are GBs unused seems to be a bad optimization.
True, but this adds complexity. We could land with a hard-coded cap and then change to a calculation in future releases if it's a problem.
| Assignee | ||
Comment 39•9 years ago
|
||
> > 3) Does Android have a maximum file node limit? What about per app?
Each Android device can have a different set of filesystems in use (yay!). Some notes on the common ones:
* FAT32 can be used on x86 Android devices – limit of 65,536 "entries" per directory, where a file can take up multiple entries for long file names (http://stackoverflow.com/a/2652238)
* yaffs2 is the most common for old devices – no hard limit [1]
* Modern devices typically run ext4 [2] – its limit is set at filesystem creation time. On my personal device, I have 39737500 used inodes for 82106210 total inodes (33%). I get the feeling we're not really making a dent in those remaining 42 million inodes. ;)
I doubt we'd exceed 65,536 entries anyway, which seems like a reasonable bound. That being said, since we killed GB, that bound is conservative.
[1]: http://www.yaffs.net/documents/faq#How_many_files_can_there_be
[2]: http://android.stackexchange.com/a/95679
[3]: http://serverfault.com/a/104989
| Assignee | ||
Comment 40•9 years ago
|
||
re where to write to the store, the upload Service or the Activity: I chose the Activity due to a short-coming for the Service: a network upload might block writing a ping to storage. This is unlikely to occur with just the core ping (since it's always store, then upload) but could become problematic as we potentially attempt to store multiple pings concurrently. Additionally, in order to get around this, we'd have to design when each ping is expected to access the Service, which 1) may not be feasible and 2) more tightly couples the various ping types to one another.
That being said, with the Activity approach, some complexity is moved to the store where the `writePingToStore` method must be concurrent with `getAllPings`, `removePing`, etc. Each Store will have to have it's own implementation and the best we can do is enforce this via a contract in the javadoc (which is possible to be done wrong :\).
We can make the CorePingStore generic to allow other pings to re-use the store and avoid breaking the contract.
| Assignee | ||
Comment 41•9 years ago
|
||
We have to use FileLock on our JSON solution: I was expecting all AtomicFile operations to occur in an artifact (e.g. "file.bak" moved to "file" on write complete) but that is not the case. My read operation was going to read `*.json`, but if the file is not named as an artifact, it can potentially be read before it is completely written. I thought about using rename as a work-around, but that is also not guaranteed to be atomic.
Comment 42•9 years ago
|
||
(In reply to Michael Comella (:mcomella) from comment #37)
> > > 2) Each ping to upload is stored in its own JSON file (influenced by Finkle)
> > > with `{server: ..., payload: ...}`. The IDs (i.e. to remove specific values)
> > > will be declared in the file name (e.g. "core_store_10.json").
> >
> > 10 is the sequence number?
>
> Yeah
I'm curious. Why do we need to save the sequence number outside the ping itself? Don't we store the next sequence number in shared prefs?
| Assignee | ||
Comment 43•9 years ago
|
||
(In reply to Mark Finkle (:mfinkle) from comment #42)
> I'm curious. Why do we need to save the sequence number outside the ping
> itself? Don't we store the next sequence number in shared prefs?
The next sequence number is stored in shared prefs. The sequence numbers outside the ping serve a different purpose: they are used to uniquely identify pings (I chose the sequence numbers because they were convenient but they can be anything). We need this after upload – the uploader will pass back the IDs of successfully uploaded pings and we'll delete those pings.
Having the IDs in the filename is an optimization – we can delete pings without reading the file contents.
Comment 44•9 years ago
|
||
(In reply to Michael Comella (:mcomella) from comment #43)
> The next sequence number is stored in shared prefs. The sequence numbers
> outside the ping serve a different purpose: they are used to uniquely
> identify pings (I chose the sequence numbers because they were convenient
> but they can be anything). We need this after upload – the uploader will
> pass back the IDs of successfully uploaded pings and we'll delete those
> pings.
>
> Having the IDs in the filename is an optimization – we can delete pings
> without reading the file contents.
OK. I think Gecko uses the docId as the ping filename, but I see what you're doing. As long as we are not encoding data into the filename for extraction, I'm fine with the plan.
| Assignee | ||
Comment 45•9 years ago
|
||
(In reply to Mark Finkle (:mfinkle) from comment #44)
> As long as we are not encoding data into the filename for extraction,
> I'm fine with the plan.
For my edification, why is that?
Flags: needinfo?(mark.finkle)
| Assignee | ||
Comment 46•9 years ago
|
||
Review commit: https://reviewboard.mozilla.org/r/49579/diff/#index_header
See other reviews: https://reviewboard.mozilla.org/r/49579/
Attachment #8742955 -
Attachment description: MozReview Request: Bug 1243585 - Add Telemetry*Scheduler. r=sebastian → MozReview Request: Bug 1243585 - Add UploadAllPingsImmediatelyScheduler and tests. r=sebastian
Attachment #8743535 -
Attachment description: MozReview Request: Bug 1243585 - Add methods to CorePingBuilder to generate a builder. r=sebastian r=sebastian → MozReview Request: Bug 1243585 - Add methods to CorePingBuilder to generate a builder. r=sebastian
| Assignee | ||
Comment 47•9 years ago
|
||
Review commit: https://reviewboard.mozilla.org/r/49581/diff/#index_header
See other reviews: https://reviewboard.mozilla.org/r/49581/
| Assignee | ||
Comment 48•9 years ago
|
||
There is less to store on disk and it's probably more correct.
Review commit: https://reviewboard.mozilla.org/r/49583/diff/#index_header
See other reviews: https://reviewboard.mozilla.org/r/49583/
| Assignee | ||
Comment 49•9 years ago
|
||
I would have done this sooner but it's a version control nightmare.
I made the change because it's harder to grep for logs when the logtag doesn't
include "Telemetry".
Review commit: https://reviewboard.mozilla.org/r/49585/diff/#index_header
See other reviews: https://reviewboard.mozilla.org/r/49585/
| Assignee | ||
Comment 50•9 years ago
|
||
Comment on attachment 8742953 [details]
MozReview Request: Bug 1243585 - Create telemtry/core/ pkg and move files accordingly. r=sebastian
Review request updated; see interdiff: https://reviewboard.mozilla.org/r/47491/diff/2-3/
| Assignee | ||
Comment 51•9 years ago
|
||
Comment on attachment 8742954 [details]
MozReview Request: Bug 1243585 - Move Intent constants into UploadService. r=sebastian
Review request updated; see interdiff: https://reviewboard.mozilla.org/r/47493/diff/2-3/
| Assignee | ||
Comment 52•9 years ago
|
||
Comment on attachment 8742956 [details]
MozReview Request: Bug 1243585 - Add TelemetryDispatcher. r=sebastian
Review request updated; see interdiff: https://reviewboard.mozilla.org/r/47497/diff/2-3/
| Assignee | ||
Comment 53•9 years ago
|
||
Comment on attachment 8742955 [details]
MozReview Request: Bug 1243585 - Add UploadAllPingsImmediatelyScheduler and tests. r=sebastian
Review request updated; see interdiff: https://reviewboard.mozilla.org/r/47495/diff/2-3/
| Assignee | ||
Comment 54•9 years ago
|
||
Comment on attachment 8743537 [details]
MozReview Request: Bug 1243585 - Revise TelemetryUploadService for new store. r=sebastian
Review request updated; see interdiff: https://reviewboard.mozilla.org/r/47873/diff/1-2/
| Assignee | ||
Comment 55•9 years ago
|
||
Comment on attachment 8743538 [details]
MozReview Request: Bug 1243585 - Remove unused BackgroundService & related code. r=sebastian
Review request updated; see interdiff: https://reviewboard.mozilla.org/r/47875/diff/1-2/
| Assignee | ||
Comment 56•9 years ago
|
||
Comment on attachment 8743535 [details]
MozReview Request: Bug 1243585 - Add methods to CorePingBuilder to generate a builder. r=sebastian
Review request updated; see interdiff: https://reviewboard.mozilla.org/r/47869/diff/1-2/
| Assignee | ||
Comment 57•9 years ago
|
||
Comment on attachment 8743536 [details]
MozReview Request: Bug 1243585 - Create CorePingBuilder in BrowserApp. r=sebastian
Review request updated; see interdiff: https://reviewboard.mozilla.org/r/47871/diff/1-2/
| Assignee | ||
Comment 58•9 years ago
|
||
This is working locally. Still TODO:
* Each ping sent up creates a new HTTP connection because I didn't change the existing BaseResource code. This caused me to get rate limited by my test server (and the same would probably happen from our telemetry server). We should try to combine them (if BaseResource makes this feasible, otherwise it's better as a follow-up)
* I want to move *Builder into a pingbuilder/ package
* I could be better about short-circuiting the Intent handling in the background service when there are no pings in the store (I don't know that I can completely remove them from the queue though)
| Assignee | ||
Comment 59•9 years ago
|
||
(In reply to Michael Comella (:mcomella) from comment #58)
> This is working locally. Still TODO:
> * Each ping sent up creates a new HTTP connection because I didn't change
> the existing BaseResource code. This caused me to get rate limited by my
> test server (and the same would probably happen from our telemetry server).
> We should try to combine them (if BaseResource makes this feasible,
> otherwise it's better as a follow-up)
Actually, it's unclear the telemetry server would accept multiple pings over the same connection.
Georg, can the telemetry server accept multiple pings over the same HTTP connection, or do I have to reconnect to send another ping? Also, is the telemetry server rate limited? If so, do you know under which metrics?
Flags: needinfo?(gfritzsche)
| Assignee | ||
Comment 60•9 years ago
|
||
(In reply to Michael Comella (:mcomella) from comment #58)
> * I could be better about short-circuiting the Intent handling in the
> background service when there are no pings in the store (I don't know that I
> can completely remove them from the queue though)
I added short-circuits in:
* TelemetryUploadService.uploadPendingPingsFromStore when store.getAllPings returns 0
* TelemetryJSONFilePingStore.onUploadAttemptComplete when the successful upload ID set is empty
This isn't ideal (e.g. we could cancel the service altogether) but my brief skim doesn't see a clean way to do that with the current code.
> * Each ping sent up creates a new HTTP connection because I didn't change
> the existing BaseResource code. This caused me to get rate limited by my
> test server (and the same would probably happen from our telemetry server).
> We should try to combine them (if BaseResource makes this feasible,
> otherwise it's better as a follow-up)
Let's do a follow-up (based on Georg's response).
| Assignee | ||
Comment 61•9 years ago
|
||
Ideally, we'd just not run the service but skimming, I see no clean way to do
that with the existing code.
Review commit: https://reviewboard.mozilla.org/r/49833/diff/#index_header
See other reviews: https://reviewboard.mozilla.org/r/49833/
Attachment #8747323 -
Flags: review?(s.kaspari)
Attachment #8747324 -
Flags: review?(s.kaspari)
Attachment #8747325 -
Flags: review?(s.kaspari)
| Assignee | ||
Comment 62•9 years ago
|
||
I would have folded this but I screwed up but the version control is getting
messy.
Review commit: https://reviewboard.mozilla.org/r/49835/diff/#index_header
See other reviews: https://reviewboard.mozilla.org/r/49835/
| Assignee | ||
Comment 63•9 years ago
|
||
This overwrites a commit I did at the beginning, but fixing the version control
would have been a waste of time.
Review commit: https://reviewboard.mozilla.org/r/49837/diff/#index_header
See other reviews: https://reviewboard.mozilla.org/r/49837/
| Assignee | ||
Comment 64•9 years ago
|
||
Comment on attachment 8747325 [details]
MozReview Request: Bug 1243585 - Move ping builders -> pingbuilders/. r=sebastian
Review request updated; see interdiff: https://reviewboard.mozilla.org/r/49837/diff/1-2/
| Assignee | ||
Comment 65•9 years ago
|
||
(In reply to Michael Comella (:mcomella) from comment #60)
> Let's do a follow-up (based on Georg's response).
Filed bug 1269035 and moved NI to bug 1269035 comment 1.
Flags: needinfo?(gfritzsche)
| Assignee | ||
Updated•9 years ago
|
Attachment #8742953 -
Flags: review?(s.kaspari)
Attachment #8742954 -
Flags: review?(s.kaspari)
Attachment #8746869 -
Flags: review?(s.kaspari)
Attachment #8742956 -
Flags: review?(s.kaspari)
Attachment #8742955 -
Flags: review?(s.kaspari)
Attachment #8746870 -
Flags: review?(s.kaspari)
Attachment #8743537 -
Flags: review?(s.kaspari)
Attachment #8743538 -
Flags: review?(s.kaspari)
Attachment #8743535 -
Flags: review?(s.kaspari)
Attachment #8743536 -
Flags: review?(s.kaspari)
Attachment #8746871 -
Flags: review?(s.kaspari)
Attachment #8746872 -
Flags: review?(s.kaspari)
Comment 66•9 years ago
|
||
Comment on attachment 8742953 [details]
MozReview Request: Bug 1243585 - Create telemtry/core/ pkg and move files accordingly. r=sebastian
https://reviewboard.mozilla.org/r/47491/#review46707
Attachment #8742953 -
Flags: review?(s.kaspari) → review+
Comment 67•9 years ago
|
||
Comment on attachment 8742954 [details]
MozReview Request: Bug 1243585 - Move Intent constants into UploadService. r=sebastian
https://reviewboard.mozilla.org/r/47493/#review46709
Attachment #8742954 -
Flags: review?(s.kaspari) → review+
Comment 68•9 years ago
|
||
Comment on attachment 8746869 [details]
MozReview Request: Bug 1243585 - Add interfaces to be used by dispatcher. r=sebastian
https://reviewboard.mozilla.org/r/49579/#review46719
::: mobile/android/base/java/org/mozilla/gecko/telemetry/TelemetryPingFromStore.java:14
(Diff revision 1)
> +
> +/**
> + * Container for telemetry data and the data necessary to upload it, as
> + * returned by a {@link TelemetryPingStore}.
> + */
> +public class TelemetryPingFromStore extends TelemetryPing {
Doesn't the ping already have a unique id / sequence number? Why do we wrap the ping again?
::: mobile/android/base/java/org/mozilla/gecko/telemetry/TelemetryPingFromStore.java:17
(Diff revision 1)
> + * returned by a {@link TelemetryPingStore}.
> + */
> +public class TelemetryPingFromStore extends TelemetryPing {
> + private final int uniqueID;
> +
> + public TelemetryPingFromStore(final String url, final ExtendedJSONObject payload, final int uniqueID) {
(Offtopic): I wonder why we chose ExtendedJSONObject (-> org.json.simple.JSONObject) here instead of org.json.JSONObject? Do we have a bug filed to replace it? It seems to be odd that we want to remove it but add new code with it here.
::: mobile/android/base/java/org/mozilla/gecko/telemetry/stores/TelemetryPingStore.java:22
(Diff revision 1)
> +/**
> + * Persistent storage for TelemetryPings that are queued for upload.
> + *
> + * An implementation of this class is expected to be thread-safe.
> + */
> +public interface TelemetryPingStore extends Parcelable {
This interface and TelemetryUploadScheduler are clean and I like how they separate the interface from the separation. However I wonder if they negatively affect the method count with not adding much value: Will there ever be more than one implementation?
I was curios to see what others think about that and found those blog posts (plain Java, non Android, so they do not mention method count):
* https://www.symphonious.net/2011/06/18/the-single-implementation-fallacy/
* http://www.adam-bien.com/roller/abien/entry/service_s_new_serviceimpl_why
::: mobile/android/base/java/org/mozilla/gecko/telemetry/stores/TelemetryPingStore.java:27
(Diff revision 1)
> +public interface TelemetryPingStore extends Parcelable {
> +
> + /**
> + * @return a list of all the telemetry pings in the store that are ready for upload.
> + */
> + ArrayList<TelemetryPingFromStore> getAllPings();
If the store can potentially hold a lot of pings then maybe we just want to have a method for getting the next ping to upload? (Do we always want to load all pings into memory before uploading?)
nit: Do we need to be specific about the type of list or can this be <List>?
Attachment #8746869 -
Flags: review?(s.kaspari) → review+
Comment 69•9 years ago
|
||
Comment on attachment 8742956 [details]
MozReview Request: Bug 1243585 - Add TelemetryDispatcher. r=sebastian
https://reviewboard.mozilla.org/r/47497/#review46725
::: mobile/android/base/java/org/mozilla/gecko/telemetry/TelemetryDispatcher.java:58
(Diff revision 3)
> + private static final String STORE_CONTAINER_DIR_NAME = "telemetry_java";
> + private static final String CORE_STORE_DIR_NAME = "core";
> +
> + private final JSONFilePingStore coreStore;
> +
> + private final TelemetryUploadAllPingsImmediatelyScheduler uploadAllPingsImmediatelyScheduler;
nit: You do not use the interface here?
::: mobile/android/base/java/org/mozilla/gecko/telemetry/TelemetryDispatcher.java:60
(Diff revision 3)
> +
> + private final JSONFilePingStore coreStore;
> +
> + private final TelemetryUploadAllPingsImmediatelyScheduler uploadAllPingsImmediatelyScheduler;
> +
> + public TelemetryDispatcher(final String profilePath) {
At this point I wonder where the callers get the dispatcher from. Will there be multiple instances!? Or are you focussing on the core ping for now?
::: mobile/android/base/java/org/mozilla/gecko/telemetry/TelemetryDispatcher.java:73
(Diff revision 3)
> + final QueuePingRunnable runnable = new QueuePingRunnable(context, uniqueID, ping, store, scheduler);
> + ThreadUtils.postToBackgroundThread(runnable); // TODO: Investigate how busy this thread is. See if we want another.
A separate thread with handler could avoid creating a Runnable for every ping. But maybe that's neglectable.
::: mobile/android/base/java/org/mozilla/gecko/telemetry/TelemetryDispatcher.java:82
(Diff revision 3)
> + /**
> + * Queues the given ping for upload and potentially schedules upload. This method can be called from any thread.
> + */
> + public void queuePingForUpload(final Context context, final TelemetryCorePingBuilder pingBuilder) {
> + final TelemetryPing ping = pingBuilder.build();
> + final int id = ping.getPayload().getIntegerSafely(TelemetryCorePingBuilder.SEQ);
I wonder why we extract the id here, only to forward it multiple times so that the store has it. As the store gets the ping object itself - should this be a method on the ping and the store just calls it?
::: mobile/android/base/java/org/mozilla/gecko/telemetry/TelemetryDispatcher.java:104
(Diff revision 3)
> + final Context context = contextWeakReference.get();
> + if (context == null) {
> + return;
> + }
> +
If you make sure that you have the application context in queuePing*() (getApplicationContext()) then you do not need to add all the weak reference code.
Attachment #8742956 -
Flags: review?(s.kaspari) → review+
Updated•9 years ago
|
Attachment #8742955 -
Flags: review?(s.kaspari) → review+
Comment 70•9 years ago
|
||
Comment on attachment 8742955 [details]
MozReview Request: Bug 1243585 - Add UploadAllPingsImmediatelyScheduler and tests. r=sebastian
https://reviewboard.mozilla.org/r/47495/#review46733
Comment 71•9 years ago
|
||
Comment on attachment 8746870 [details]
MozReview Request: Bug 1243585 - Add JSONFilePingStore with tests. r=sebastian
https://reviewboard.mozilla.org/r/49581/#review46741
::: mobile/android/base/java/org/mozilla/gecko/telemetry/stores/JSONFilePingStore.java:60
(Diff revision 1)
> + private static final String FILENAME = "ping-%s.json";
> + private static final Pattern FILENAME_PATTERN = Pattern.compile("ping-([0-9]+)\\.json");
Looking at this duplication I wish there would be one pattern for matching and generating/formating this. :)
::: mobile/android/base/java/org/mozilla/gecko/telemetry/stores/JSONFilePingStore.java:63
(Diff revision 1)
> + // We keep the key names short to reduce storage size impact.
> + @VisibleForTesting static final String KEY_PAYLOAD = "p";
> + @VisibleForTesting static final String KEY_URL = "u";
Is it really worth it? If we are so much concerned about size, why don't we GZIP or use a more efficient format (BSON/Protocol Buffers).
::: mobile/android/base/java/org/mozilla/gecko/telemetry/stores/JSONFilePingStore.java:108
(Diff revision 1)
> + final FileOutputStream outputStream = new FileOutputStream(getPingFile(uniqueID), false);
> + blockForLockAndWriteFileAndCloseStream(outputStream, output);
> + }
> +
> + @Override
> + public void maybePrunePings() {
It would be interesting to see telemetry to see what this method does in the wild - but as this is the telemetry implementation this is not a good idea unfortunately. :)
::: mobile/android/base/java/org/mozilla/gecko/telemetry/stores/JSONFilePingStore.java:143
(Diff revision 1)
> + getPingFile(id).delete();
> + }
> + }
> +
> + @Override
> + public ArrayList<TelemetryPingFromStore> getAllPings() {
I'm still trying to understand why we want to load all of them at once instead of one by one.
::: mobile/android/base/java/org/mozilla/gecko/telemetry/stores/JSONFilePingStore.java:203
(Diff revision 1)
> + * Note: this method blocks until a file lock can be acquired.
> + */
> + private static void blockForLockAndWriteFileAndCloseStream(final FileOutputStream outputStream, final String str)
> + throws IOException {
> + try {
> + final FileLock lock = outputStream.getChannel().lock(0, Long.MAX_VALUE, false);
nit: Isn't this the same as calling lock() without parameters?
::: mobile/android/base/java/org/mozilla/gecko/telemetry/stores/JSONFilePingStore.java:223
(Diff revision 1)
> + * Note: this method returns null when a lock could not be acquired.
> + */
> + private static JSONObject lockAndReadFileAndCloseStream(final FileInputStream inputStream, final int fileSize)
> + throws IOException, JSONException {
> + try {
> + final FileLock lock = inputStream.getChannel().tryLock(0, Long.MAX_VALUE, true); // null when lock not acquired
Why is this lock shared (true)?
::: mobile/android/base/java/org/mozilla/gecko/telemetry/stores/JSONFilePingStore.java:232
(Diff revision 1)
> + // The file lock is released when the stream is closed. If we try to redundantly close it, we get
> + // a ClosedChannelException. To be safe, we could catch that every time but there is a performance
> + // hit to exception handling so instead we assume the file lock will be closed.
> + return new JSONObject(FileUtils.readStringFromInputStreamAndCloseStream(inputStream, fileSize));
> + } finally {
> + inputStream.close(); // redundant: closed when the steram is closed, but let's be safe.
nit: typo "steram"
::: mobile/android/base/java/org/mozilla/gecko/telemetry/stores/JSONFilePingStore.java:257
(Diff revision 1)
> +
> + return idsToFilter.contains(getIDFromFilename(filename));
> + }
> + }
> +
> + public static final Parcelable.Creator<JSONFilePingStore> CREATOR = new Parcelable.Creator<JSONFilePingStore>() {
This is quite complex. Are we going to have multiple stores and the service has to work with multiple implementations?!
Attachment #8746870 -
Flags: review?(s.kaspari) → review+
Comment 72•9 years ago
|
||
Comment on attachment 8743537 [details]
MozReview Request: Bug 1243585 - Revise TelemetryUploadService for new store. r=sebastian
https://reviewboard.mozilla.org/r/47873/#review46751
::: mobile/android/base/java/org/mozilla/gecko/telemetry/TelemetryUploadService.java:72
(Diff revision 2)
> + private static void uploadPendingPingsFromStore(final TelemetryPingStore store) {
> + final ArrayList<TelemetryPingFromStore> pingsToUpload = store.getAllPings();
> +
> + final HashSet<Integer> successfulUploadIDs = new HashSet<>(pingsToUpload.size()); // used for side effects.
> + final PingResultDelegate delegate = new PingResultDelegate(successfulUploadIDs);
> + for (final TelemetryPingFromStore ping : pingsToUpload) {
If we are uploading the pings one-by-one then why are we reading all and only after sending all we start to delete them?
As this can be interrupted at any time, doesn't it make more sense to read,upload,delete in a loop?
::: mobile/android/base/java/org/mozilla/gecko/telemetry/TelemetryUploadService.java:74
(Diff revision 2)
> + if (delegate.hadConnectionError()) {
> + break;
> + }
nit: Shouldn't this be at the end of the loop? Technically it doesn't matter but reading about the error case first is confusing ("Why error? Where was the request?").
::: mobile/android/base/java/org/mozilla/gecko/telemetry/TelemetryUploadService.java:78
(Diff revision 2)
> + // TODO: It'd be great to re-use the same HTTP connection for each upload request.
> + delegate.setPingID(ping.getUniqueID());
> + uploadPing(ping, delegate);
I feel like the Resource and Delegate classes add some level of complexity here (maybe I'm just not used to them) that is hard to follow for something as simple as an uploader. And then they make things worse (connection not reused), so what did we win?
::: mobile/android/base/java/org/mozilla/gecko/util/NetworkUtils.java:24
(Diff revision 2)
> + final NetworkInfo networkInfo = getActiveNetworkInfo(context);
> + return networkInfo != null &&
> + networkInfo.isConnected();
> + }
> +
> + public static boolean isBackgroundDataEnabled(final Context context) {
nit: From the method signature I expect this to return false if the user has restricted background data. But it seems like this is not necessarily the case because this method also checks if I'm currently connected or connecting to a network.
Attachment #8743537 -
Flags: review?(s.kaspari) → review+
Comment 73•9 years ago
|
||
Comment on attachment 8743538 [details]
MozReview Request: Bug 1243585 - Remove unused BackgroundService & related code. r=sebastian
https://reviewboard.mozilla.org/r/47875/#review46757
Attachment #8743538 -
Flags: review?(s.kaspari) → review+
Comment 74•9 years ago
|
||
Comment on attachment 8743535 [details]
MozReview Request: Bug 1243585 - Add methods to CorePingBuilder to generate a builder. r=sebastian
https://reviewboard.mozilla.org/r/47869/#review46763
::: mobile/android/base/java/org/mozilla/gecko/telemetry/core/TelemetryCorePingBuilder.java:156
(Diff revision 2)
> + // TODO (bug 1241685): Sync this preference with the gecko preference.
> + return sharedPrefs.getString(TelemetryConstants.PREF_SERVER_URL, TelemetryConstants.DEFAULT_SERVER_URL);
> + }
> +
> + @WorkerThread // synchronous shared prefs write.
> + public static int getAndIncrementSequenceNumberSync(final SharedPreferences sharedPrefsForProfile) {
Shouldn't this be synchronized to avoid that this can return the same sequence number for multiple threads?
::: mobile/android/base/java/org/mozilla/gecko/telemetry/core/TelemetryCorePingBuilder.java:159
(Diff revision 2)
> + // We store synchronously before constructing to ensure this sequence number will not be re-used.
> + sharedPrefsForProfile.edit().putInt(TelemetryConstants.PREF_SEQ_COUNT, seq + 1).commit();
You do not need to do this. apply() does write to disk asynchronously but the in-memory cache is updated synchronously: Readers will get the new value.
::: mobile/android/base/java/org/mozilla/gecko/telemetry/core/TelemetryCorePingBuilder.java:180
(Diff revision 2)
> + }
> +
> + /**
> + * @return the search engine identifier in the format expected by the core ping.
> + */
> + public static String getEngineIdentifier(final SearchEngine searchEngine) {
nit: @nullable ?
Attachment #8743535 -
Flags: review?(s.kaspari) → review+
Comment 75•9 years ago
|
||
Comment on attachment 8743536 [details]
MozReview Request: Bug 1243585 - Create CorePingBuilder in BrowserApp. r=sebastian
https://reviewboard.mozilla.org/r/47871/#review46775
::: mobile/android/base/java/org/mozilla/gecko/BrowserApp.java:317
(Diff revision 2)
> ));
>
> @NonNull
> private SearchEngineManager searchEngineManager; // Contains reference to Context - DO NOT LEAK!
>
> + private TelemetryDispatcher mTelemetryDispatcher;
So the Dispatcher is only for the core ping for now? Otherwise it would be awkward to have it attached to the BrowserApp instance.
::: mobile/android/base/java/org/mozilla/gecko/BrowserApp.java:4081
(Diff revision 2)
> // Only slide the urlbar out if it was hidden when the action mode started
> // Don't animate hiding it so that there's no flash as we switch back to url mode
> mDynamicToolbar.setTemporarilyVisible(false, VisibilityTransition.IMMEDIATE);
> }
>
> - @WorkerThread // synchronous SharedPrefs write.
> + private static class UploadTelemetryCorePingCallback implements SearchEngineManager.SearchEngineCallback {
nit: If this class is static anyways, should we move it outside of BrowserApp?
Attachment #8743536 -
Flags: review?(s.kaspari) → review+
Updated•9 years ago
|
Attachment #8746871 -
Flags: review?(s.kaspari) → review+
Comment 76•9 years ago
|
||
Comment on attachment 8746871 [details]
MozReview Request: Bug 1243585 - Get server url from prefs at upload time. r=sebastian
https://reviewboard.mozilla.org/r/49583/#review46961
Comment 77•9 years ago
|
||
Comment on attachment 8746872 [details]
MozReview Request: Bug 1243585 - Rename JSONFilePingStore -> TelemetryJSONFilePingStore. r=sebastian
https://reviewboard.mozilla.org/r/49585/#review46965
::: mobile/android/base/java/org/mozilla/gecko/telemetry/stores/TelemetryJSONFilePingStore.java:56
(Diff revision 1)
> * be currently written
> * * no locking: {@link #onUploadAttemptComplete(Set)} deletes the given pings, none of which should be
> * currently written
> */
> -public class JSONFilePingStore implements TelemetryPingStore {
> - private static final String LOGTAG = "Gecko" + JSONFilePingStore.class.getSimpleName();
> +public class TelemetryJSONFilePingStore implements TelemetryPingStore {
> + private static final String LOGTAG = "Gecko" + TelemetryJSONFilePingStore.class.getSimpleName();
nit: This is already way longer than the recommended 23 characters.
Attachment #8746872 -
Flags: review?(s.kaspari) → review+
Comment 78•9 years ago
|
||
Comment on attachment 8747323 [details]
MozReview Request: Bug 1243585 - Add short-circuits when there are no pings. r=sebastian
https://reviewboard.mozilla.org/r/49833/#review46969
::: mobile/android/base/java/org/mozilla/gecko/telemetry/TelemetryUploadService.java:70
(Diff revision 1)
> private static void uploadPendingPingsFromStore(final Context context, final TelemetryPingStore store) {
> final ArrayList<TelemetryPingFromStore> pingsToUpload = store.getAllPings();
> - final String serverSchemeHostPort = getServerSchemeHostPort(context);
> + if (pingsToUpload.isEmpty()) {
> + return true;
Return true from a void method? Is this an intermediate state?
Attachment #8747323 -
Flags: review?(s.kaspari) → review+
Updated•9 years ago
|
Attachment #8747324 -
Flags: review?(s.kaspari) → review+
Comment 79•9 years ago
|
||
Comment on attachment 8747324 [details]
MozReview Request: Bug 1243585 - Stop IntentService if there is a connection failure. r=sebastian
https://reviewboard.mozilla.org/r/49835/#review46971
::: mobile/android/base/java/org/mozilla/gecko/telemetry/TelemetryUploadService.java:70
(Diff revision 1)
> + // If we had an upload failure, we should stop the IntentService and drop any
> + // pending Intents in the queue so we don't waste resources (e.g. battery)
> + // trying to upload when there's likely to be another connection failure.
Oh, nice. I didn't know that stopSelf() will flush the queue.
Updated•9 years ago
|
Attachment #8747325 -
Flags: review?(s.kaspari) → review+
Comment 80•9 years ago
|
||
Comment on attachment 8747325 [details]
MozReview Request: Bug 1243585 - Move ping builders -> pingbuilders/. r=sebastian
https://reviewboard.mozilla.org/r/49837/#review46973
| Assignee | ||
Comment 81•9 years ago
|
||
https://reviewboard.mozilla.org/r/49579/#review46719
> Doesn't the ping already have a unique id / sequence number? Why do we wrap the ping again?
The seq nunmber is specific to the core ping and may not exist in other ping types so we wrap the ping with a unique ID that allows each ping type to come up with their own unique ID. I'll add a comment.
> (Offtopic): I wonder why we chose ExtendedJSONObject (-> org.json.simple.JSONObject) here instead of org.json.JSONObject? Do we have a bug filed to replace it? It seems to be odd that we want to remove it but add new code with it here.
`ExtendedJSONObject` was the easiest to use `BaseResource` with which Richard & Nick insisted I use because it already knows how to talk to sync servers. That being said, the abstraction is kind of a pain in the ass (e.g. using ExtendedJSONObject, can we share a HTTP connection for multiple uploads) so as part of bug 1269035, I'll investigate why it's still useful.
> This interface and TelemetryUploadScheduler are clean and I like how they separate the interface from the separation. However I wonder if they negatively affect the method count with not adding much value: Will there ever be more than one implementation?
>
> I was curios to see what others think about that and found those blog posts (plain Java, non Android, so they do not mention method count):
> * https://www.symphonious.net/2011/06/18/the-single-implementation-fallacy/
> * http://www.adam-bien.com/roller/abien/entry/service_s_new_serviceimpl_why
I expect there to be more than one implementation. We are already looking to add the main and core ping to this uploader and I don't think we'll want to 1) copy all of the existing main pings saved by Gecko into our JSON file store and 2) upload everything immediately, all the time for the larger pings.
As for method count, Facebook's redex actually gets rid of interfaces that have only one implementation.
I agree with many of the concerns of the articles (I'm happy to learn that the `Impl` naming pattern is a dead giveaway! :P) but I think they also leave out one other benefit of interfaces – intent. A clean interface distinctly shows that this type of Object is intended for this purpose, which can be hard to get out of a fully-implemented class (and its potentially out of date documentation). This works well for the initial implementation but I'm skeptical of how it may grow over time – in order to get something fixed quickly, a developer can just add a few methods to the interface, which voids the benefit I just mentioned.
Is it worth it? I think it depends on the case, but I'm not sure yet.
But again, I expect there to be more than one implementation.
> If the store can potentially hold a lot of pings then maybe we just want to have a method for getting the next ping to upload? (Do we always want to load all pings into memory before uploading?)
>
> nit: Do we need to be specific about the type of list or can this be <List>?
> If the store can potentially hold a lot of pings then maybe we just want to have a method for getting the next ping to upload? (Do we always want to load all pings into memory before uploading?)
In theory, a store can hold a lot of pings. However, I feel we should keep this number down because all of the data can be uploaded at once. If we're afraid about loading it all into memory at once, I think we should be equally afraid about uploading it all at once.
That being said, I think `getAllPings` is much simpler – `getNextPing` (or similar) requires you to maintain state – either which ping is next or which ping you last received (so the store can infer what's next). How does this state change if Fennec starts adding pings? Or if we decide to upload a ping, delete it, then upload the next ping, etc. `getAllPings` works as a snapshot that prevents us from having to think about these issues. If we need to optimize it further, I think we can change it later.
> nit: Do we need to be specific about the type of list or can this be <List>?
No – I'll change it.
| Assignee | ||
Comment 82•9 years ago
|
||
https://reviewboard.mozilla.org/r/47497/#review46725
> nit: You do not use the interface here?
Why do you feel it's beneficial to do so? I use the interface for my generic `QueuePingRunnable` code.
> At this point I wonder where the callers get the dispatcher from. Will there be multiple instances!? Or are you focussing on the core ping for now?
In the current design, the Dispatcher is created by BrowserApp so there'd be only one instance.
I actually didn't consider how a Dispatcher might work with multiple activities – oops! That being said, the Dispatcher currently contains several other stateless components so in theory, provided we set up the right concurrency model in the stores, we could have multiple instances. However, given the current state of the app and how it's changed over the past few years, I think we're unlikely to have to run this from multiple activities.
> Or are you focussing on the core ping for now?
I'm not sure what you mean by this.
> A separate thread with handler could avoid creating a Runnable for every ping. But maybe that's neglectable.
True - I didn't consider that. In theory, we don't even need a separate thread because we can use the background thread handler.
Do you have an opinion on how to go about optimizing memory use before there's an issue? I've started to use a policy like, "Optimize if it's simple & still readable, or if it's an obvious pitfall (e.g. allocating in an inner loop) but otherwise keep the code readable and easy to write."
In this case, overriding `handleMessage` for the background thread is less clear and forces a context switch so I think it's simpler to make runnables.
> I wonder why we extract the id here, only to forward it multiple times so that the store has it. As the store gets the ping object itself - should this be a method on the ping and the store just calls it?
Good idea! I removed `TelemetryPingFromStore` and added the unique ID to the `TelemetryPing` class.
| Assignee | ||
Comment 83•9 years ago
|
||
https://reviewboard.mozilla.org/r/49581/#review46741
> Is it really worth it? If we are so much concerned about size, why don't we GZIP or use a more efficient format (BSON/Protocol Buffers).
It seemed like an easy optimization without many disadvantages – this object is kept local to the Store code, in which context these shortened tags are unideal but not too challenging to understand. Then again, I suppose a similar argument can be made against this as one could make against single letter variable names...
As to your suggested alternatives, GZIP/BSON/Protocol Buffers requires overhead in understanding how these formats work, perhaps a less human-readable format on disk (though we're probably not looking at that), pulling in external libs, etc. It's a lot more complicated than removing a few characters from the key.
That being said, I could be convinced to make the keys longer (or implement a better compression algorithm in a follow-up – it'd be useful for larger pings like the main ping).
> I'm still trying to understand why we want to load all of them at once instead of one by one.
I responded to this earlier – let me know if you still have questions.
> nit: Isn't this the same as calling lock() without parameters?
It is, but I thought it'd be good to be explicit considering we make a similar call elsewhere.
> Why is this lock shared (true)?
While it's not useful for our code, a read lock can be shared amongst multiple readers.
Android (or java?) also made a funny "optimization" where InputStream (or maybe it was OutputStream...) threw when I used the unideal lock (i.e. exclusive for read or shared for reading). That probably influenced this decision.
> This is quite complex. Are we going to have multiple stores and the service has to work with multiple implementations?!
I agree – this is overly complex. The general idea is that we pass a store reference to the UploadService but the Intent abstraction prevents us from passing it directly. Instead we have to create a new instance with Parcelable. This works given our Store is currently stateless, but could cause problems in the future if we need to maintain state. I'll add a comment to `TelemetryPingStore` (which is also not ideal because people will change the json store without looking at the interface).
I chose to do this over the alternative of creating a singleton instance, but honestly, I didn't think as hard about it as maybe I should have. I figured maintaining state consistency in a singleton instance is also challenging, singletons make things challenging to test, and singletons kind of break the "Object" abstraction, so I opted to pass the instance through.
Do you have any opinions?
| Assignee | ||
Comment 84•9 years ago
|
||
https://reviewboard.mozilla.org/r/47871/#review46775
> So the Dispatcher is only for the core ping for now? Otherwise it would be awkward to have it attached to the BrowserApp instance.
What do you mean by this? Specifically, what do you mean by attached? And why would it be awkward?
I intend for the Dispatcher to be used by many different types of pings.
| Assignee | ||
Comment 85•9 years ago
|
||
https://reviewboard.mozilla.org/r/49833/#review46969
> Return true from a void method? Is this an intermediate state?
Yeah, I must have botched my histedits – it was messy.
| Assignee | ||
Comment 86•9 years ago
|
||
https://reviewboard.mozilla.org/r/47869/#review46763
> Shouldn't this be synchronized to avoid that this can return the same sequence number for multiple threads?
Curious – I've never thought about how stateful static methods should be managed!
We don't intend for this to be used concurrently, so I'd prefer to just add a comment explaining this method isn't thread safe for the same reason why you wouldn't try to make every object thread safe. But then again, maybe people think about using objects on multiple threads more than calling static methods from multiple threads.
Do you still feel this should be `synchronized`?
(fwiw, I added a comment)
| Assignee | ||
Comment 87•9 years ago
|
||
https://reviewboard.mozilla.org/r/47873/#review46751
> If we are uploading the pings one-by-one then why are we reading all and only after sending all we start to delete them?
>
> As this can be interrupted at any time, doesn't it make more sense to read,upload,delete in a loop?
I think it's conceptually simpler to do batch operations (i.e. read all, upload all, remove all), which is why I defaulted to them.
> As this can be interrupted at any time, doesn't it make more sense to read,upload,delete in a loop?
I think there is value in the simplicity of `getAllPings` and if we're able to re-use the HTTP connection, we'll likely do "read all, upload all, delete all".
However, if we can't re-use the connection, it could be valuable to "read all, upload one, delete one, upload one, delete..." to avoid reuploading (and wasting user data). fwiw, some stores may not do this efficient though (e.g. it's probably better to mass write a SQL store).
I'll investigate with bug 1269035.
> I feel like the Resource and Delegate classes add some level of complexity here (maybe I'm just not used to them) that is hard to follow for something as simple as an uploader. And then they make things worse (connection not reused), so what did we win?
Nick & Richard thought it was a good idea because it's already configured to talk to the sync servers but it's a tough abstraction that I'd be open to replacing.
> nit: From the method signature I expect this to return false if the user has restricted background data. But it seems like this is not necessarily the case because this method also checks if I'm currently connected or connecting to a network.
I don't have a good understanding of the ConnectivityManager code and I was largerly copying the existing sync implementation. I filed a follow-up to address this: bug 1269924.
| Assignee | ||
Comment 88•9 years ago
|
||
https://hg.mozilla.org/integration/fx-team/rev/ccf5c4614fa122b7e8e11afb2f0d1709489a3dd3
Bug 1243585 - Create telemtry/core/ pkg and move files accordingly. r=sebastian
https://hg.mozilla.org/integration/fx-team/rev/195a93569f4774ab5ed6805127f90b6636fc5db4
Bug 1243585 - Move Intent constants into UploadService. r=sebastian
https://hg.mozilla.org/integration/fx-team/rev/9873089948b3cc1f2106b74cdafca72e7b2cf54e
Bug 1243585 - Add interfaces to be used by dispatcher. r=sebastian
https://hg.mozilla.org/integration/fx-team/rev/59ad4c528dba2071822a1af18f5d6f0474374bdf
Bug 1243585 - Add TelemetryDispatcher. r=sebastian
https://hg.mozilla.org/integration/fx-team/rev/607a358e6551c2bfb4930a9fcb4b2b5b504acb9e
Bug 1243585 - Add UploadAllPingsImmediatelyScheduler and tests. r=sebastian
https://hg.mozilla.org/integration/fx-team/rev/8b3e5017a1b76304e5019ff6dd060434a75185fe
Bug 1243585 - Add JSONFilePingStore with tests. r=sebastian
https://hg.mozilla.org/integration/fx-team/rev/2bee657f0cabc3722d280b9318277865dddc70ea
Bug 1243585 - Revise TelemetryUploadService for new store. r=sebastian
https://hg.mozilla.org/integration/fx-team/rev/f1431f070872ae10c4a1dd7027421a9629c47746
Bug 1243585 - Remove unused BackgroundService & related code. r=sebastian
https://hg.mozilla.org/integration/fx-team/rev/7ba4686e88b97e96834c0013f443230a41ac570c
Bug 1243585 - Add methods to CorePingBuilder to generate a builder. r=sebastian
https://hg.mozilla.org/integration/fx-team/rev/8aedb24f67f07379f5f12f272865498c9f9f1d46
Bug 1243585 - Create CorePingBuilder in BrowserApp. r=sebastian
https://hg.mozilla.org/integration/fx-team/rev/587c84d54c3917dbc7148655cb11811c4aaf16d8
Bug 1243585 - Get server url from prefs at upload time. r=sebastian
https://hg.mozilla.org/integration/fx-team/rev/c0e84ccd51dee5a8069e3c2d28a446dfe9dad979
Bug 1243585 - Rename JSONFilePingStore -> TelemetryJSONFilePingStore. r=sebastian
https://hg.mozilla.org/integration/fx-team/rev/5c010359a3aa3c269829624151cb8894cd3d1e4c
Bug 1243585 - Add short-circuits when there are no pings. r=sebastian
https://hg.mozilla.org/integration/fx-team/rev/2c6f4392c34f596b63f582af89f9e5c716af4e6b
Bug 1243585 - Stop IntentService if there is a connection failure. r=sebastian
https://hg.mozilla.org/integration/fx-team/rev/0ef386b81241338fa8f01e1dd5663a1644e67090
Bug 1243585 - Move ping builders -> pingbuilders/. r=sebastian
https://hg.mozilla.org/integration/fx-team/rev/1c5f36f3b0ca560f42a72c813820941f564bb551
Bug 1243585 - review: Address comments. r=me
| Assignee | ||
Comment 89•9 years ago
|
||
Landed to reduce the overhead of working on a giant patch series. If you have any concerns about my responses to your review, please let me know – we can handle them in a follow-up.
Thanks for the thorough and fast review! :)
Comment 90•9 years ago
|
||
| bugherder | ||
https://hg.mozilla.org/mozilla-central/rev/ccf5c4614fa1
https://hg.mozilla.org/mozilla-central/rev/195a93569f47
https://hg.mozilla.org/mozilla-central/rev/9873089948b3
https://hg.mozilla.org/mozilla-central/rev/59ad4c528dba
https://hg.mozilla.org/mozilla-central/rev/607a358e6551
https://hg.mozilla.org/mozilla-central/rev/8b3e5017a1b7
https://hg.mozilla.org/mozilla-central/rev/2bee657f0cab
https://hg.mozilla.org/mozilla-central/rev/f1431f070872
https://hg.mozilla.org/mozilla-central/rev/7ba4686e88b9
https://hg.mozilla.org/mozilla-central/rev/8aedb24f67f0
https://hg.mozilla.org/mozilla-central/rev/587c84d54c39
https://hg.mozilla.org/mozilla-central/rev/c0e84ccd51de
https://hg.mozilla.org/mozilla-central/rev/5c010359a3aa
https://hg.mozilla.org/mozilla-central/rev/2c6f4392c34f
https://hg.mozilla.org/mozilla-central/rev/0ef386b81241
https://hg.mozilla.org/mozilla-central/rev/1c5f36f3b0ca
Status: NEW → RESOLVED
Closed: 9 years ago
status-firefox49:
--- → fixed
Resolution: --- → FIXED
Target Milestone: --- → Firefox 49
Comment 91•9 years ago
|
||
(In reply to Michael Comella (:mcomella) from comment #45)
> (In reply to Mark Finkle (:mfinkle) from comment #44)
> > As long as we are not encoding data into the filename for extraction,
> > I'm fine with the plan.
>
> For my edification, why is that?
Because encoding bits of useful data into the filename is a bad pattern. Encoding data that is not even required outside the ping (like the sequence number) doesn't even make sense.
I could see using the docId as the full filename. It's a UUID and would never conflict with different ping types. The docId is actually needed in the URL generation too, so using it as the filename has the benefit not needing to open the ping to get any data.
In fact, desktop/gecko uses docId as the archive filename. Did you take a look at how desktop/gecko manages archiving and resending pings?
Flags: needinfo?(mark.finkle)
| Assignee | ||
Comment 92•9 years ago
|
||
(In reply to Mark Finkle (:mfinkle) from comment #91)
> (In reply to Michael Comella (:mcomella) from comment #45)
> > (In reply to Mark Finkle (:mfinkle) from comment #44)
> > > As long as we are not encoding data into the filename for extraction,
> > > I'm fine with the plan.
> >
> > For my edification, why is that?
>
> Because encoding bits of useful data into the filename is a bad pattern.
Why is it a bad pattern? I see a series of trade-offs:
- Error-prone
+ Data is accessible without having to read the file (useful for formats that require you to read the whole file or risk complexity, like JSON)
+ Prevents duplication of data (e.g. if you need to modify it, but see also: error-prone)
To be explicit about what I'm doing, I'm saving a unique ID for the pings in the filename. This ID is not extracted to be added back to the ping, but is used by the store to identify specific pings, e.g. to remove them when an upload is completed, or (since we assume the IDs are strictly increasing) when pruning we can remove the oldest pings.
> Encoding data that is not even required outside the ping (like the sequence
> number) doesn't even make sense.
The sequence number is required for the core ping and I copy it to be the unique ID (rather than creating another arbitrary ID). The sequence number may not exist in all pings, which is why the unique ID is duplicated & separated.
> I could see using the docId as the full filename. It's a UUID and would
> never conflict with different ping types. The docId is actually needed in
> the URL generation too, so using it as the filename has the benefit not
> needing to open the ping to get any data.
I like this because it doesn't rely on the ping-creator specifying an ID that is potentially incorrect – non-unique or non-increasing. We can generate the docID ourselves under the hood and use it as the file name. We'll have to rely on file modified times (creation times are not accessible in Java 7) for pruning, but since we write the files once, this should be fine.
> In fact, desktop/gecko uses docId as the archive filename. Did you take a
> look at how desktop/gecko manages archiving and resending pings?
I have not – I'll look into it.
I filed bug 1270213 for this work.
| Assignee | ||
Comment 93•9 years ago
|
||
NI self to uplift this and friends, after validations and after it has additional data we couldn't collect before (bug 1253319). I'm thinking 48 because there is a lot of complexity here but given that there don't seem to be many regressions, I could be convinced to push it to 47 if we really need the data and releng doesn't mind.
Flags: needinfo?(michael.l.comella)
| Assignee | ||
Comment 94•9 years ago
|
||
Spoke with the interested parties I know of and we decided not to uplift this in order to reduce the amount of developer time it'd take (because the dependency graph is big and we may have already screwed up the uplift order).
Flags: needinfo?(michael.l.comella)
Updated•4 years ago
|
Product: Firefox for Android → Firefox for Android Graveyard
You need to log in
before you can comment on or make changes to this bug.
Description
•